W01 Introduction & MCDA, Multiple Criteria Decision Aid
2024-02-20-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw Dr.
參考書:
• 鄧振源書:多準則決策分析 方法與應用
• 多屬性決策分析: Multiple Attribute Decision Making: Methods and Applications [PDF]
• Fuzzy Multiple Objective Decision Making
• New Concepts and Trends of Hybrid Multiple Criteria Decision Making
陳寬裕書 -Youtube結構方程模型分析實務:SPSS與SmartPLS的運用 | 1-1 SEM結構方程模型簡介16小時學會結構方程模型:SmartPLS初階應用 |
網頁: Web Page | 參考我的筆記關於AHP層級分析法的文章。|
軟體: AHP Online Systemhtw/Lf**87 |
練習: Exc#1 | Exc#2 |
作業: 注意: 要準備一篇 投稿期刊論文 (期末要交) | [gDoc-ppt] | [DEMATEL問卷] | [DEMATEL計算] | 作業: W17截止日(2024-06-11)
期末作業-paper
同學: 有 6 個: 鴻海(土城)中央資訊處長Jacky Chen陳明勇, 澄石健康管顧楊重成城、傅茂文、企管-劉美周Ruru Tsao, 企管-劉格正
胡老師提供參考論文
1.A new hybrid MCDM model combining DANP with VIKOR to improve e-store business
2.An Analytic Network Process model for financial-crisis forecasting
3.Comments_on_Multiple_criteria_decision_making
4.Green supplier selection for sustainable development of the automotive industry using grey decision making
5.The evaluation of airline service quality by fuzzy MCDM
6.應用決策實驗室分析法(DEMATEL)與網路層級分析法(ANP)在研發專案計畫評選
7.結合決策實驗室法與網路程序分析法評估烘焙師傅於國際競賽獲獎之關鍵因素
8.運用網路程序分析法探討甄選管理師與工程師之關鍵人格特質
多準則決策 MCDM
是一種決策分析方法,用於在多個衝突的準則下選擇最佳方案。它通常用於需要考慮多個目標和準則的情況,例如在有限的資源下選擇最適合的投資項目。MCDM的核心是幫助決策者在多個準則之間進行取捨,並通過賦予不同準則權重來評估和比較不同的選擇方案。
結構方程模型SEM
則是一種統計技術,用於分析變數之間的關係,特別是潛在變數的關係。SEM結合了因素分析和路徑分析,能夠檢測變數之間的因果關係。(relationship between latent variables. SEM combines factor analysis and path analysis to detect causal relationships between variables.)這種方法常用於社會科學和行為科學,以及市場研究中,用於建立和測試理論模型,並探索不同變數之間的相互作用。
總結來說,MCDM側重於在多個準則下進行最優選擇,而SEM側重於分析變數之間的關係和因果聯繫。兩者都是強大的分析工具,但應用於不同的研究領域和目的。
In summary, MCDM focuses on optimal selection under multiple criteria, while SEM focuses on analyzing the relationships and causal links between variables. Both are powerful analytical tools but are applied in different research areas and purposes.
1.Animation: A Short Story about (MCDA) Multiple Criteria Decision Analysis
2.Intro to : Multi-Criteria Decision-Making – 1000minds
1.Introduction 2.Multiple Criteria Decision Aid, MCDA
- 商博開「定量分析」比較偏向:時間序列、和統計分析、...但我(胡老師)教的比較不偏統計。
- 結構方程模式或spss是目前當紅的method,主要探討自變數和應變數關係。
- 學「定量分析」一定要多多實做,若無實做與發表比較難懂,很快會忘掉。
- 多變量分析: 主成份 因素 ..結構方程模式..都是,包山包海。很重要。
Delphi method;
層級分析法(AHP) Analytic Hierarchy Process;
網路層級分析法(ANP) Analytic Network Process;
應用決策實驗室分析法(DEMATEL)Decision-making Trial and Evaluation Laboratory;
ISM; 等等。
其中
- AHP/ANP 主要是做(找出)關鍵因素(vital few)的, 而
- DEMATEL 主要是做因果關係。
- 老師會教原理/教工具/然而用excel都可以跑/不妨自己多找題目練習。
關於論文
@Tpic, Abstract, Keyword so important.
- 問卷至少要做幾份才夠? 有個10n法則: 如果變數(問題)有n個,問卷應>10n份。
- ??@點數不是i的,都沒有掛指導教授?為什麼?老師應當負責任-指導與監督,why?撇清嗎?跟老師合掛較好。很複雜掛不掛名掛誰名 ..或可作為題目來進行MADM研究。 所有掛名作者都在同船上 都要負責。
@期刊有 單匿名 雙匿名 審查 (作者、審查者 兩造皆不知叫雙匿名) SSCI TSSCI雙,SCI單。
斛生的老師 曾國雄教授,日本大阪大學經濟學部博士。提出DANP法。
@論文:隨時都想辦法用圖或表
-銀髮族穿戴裝置影響購買因素研究,對象未必是銀髮族-可能是其子女,買來給父母用的。
-何謂銀髮何謂高齡,都須在背景處定義出來
多看好的期刊的論文文章
• 參考 公布2022年臺灣人文及社會科學期刊評比暨核心期刊收錄評比結果暨核心期刊名單。
- 胡老師寫碩士論文時,研究日本人怎麼寫論文。 資訊管理學報、電子商務學報。這些到CEPS華藝 應該都可下載。
資訊管理Information Management
- CiNii
日本學術期刊最大的查詢入口網,由日本國立情報學研究中心(National Institute of Informatics)所建置。它收錄各學科領域的日文期刊及大學紀要,現已超過1,400萬筆資料。這是一個免費公開取用的Open Access資料庫,您可以在這裡找到豐富的資訊管理相關論文。 - Journal of Information and Management
由Japan Society for Information and Management出版,提供同行評審和免費訪問的學術文章。這個期刊涵蓋了許多資訊管理相關的主題,並且可以在J-STAGE平台上訪問。 - Save your favorite articles to refer to them later
- Get notifications for new articles that cite your favorite articles
- Search for articles quickly and easily by saving your Search history
- 台灣-國家圖書館期刊文獻資訊網
- 提供豐富的期刊相關資訊,包括中英文刊名、ISSN、出版日期、出版狀態等。這是一個很好的資源,用來尋找日文的資訊管理學術期刊。
htw_Taiwan, Welcome to My J-STAGE!
Congratulations! Your registration process is complete. You can now access your My J-STAGE account to
So, what are you waiting for? Sign in to get started!
Get started | (2024/05/14)
@查胡老師HU, YI-CHUNG的最新的期刊論文
@理論意含和實務意含 最好至少各有一篇文章可以佐證、支撐我的想法,不離譜。
結論最好提出 研究限制、和未來的研究方向。
@Construct 構念 是自概念,更高層次的抽象出來的概念。
理論如
@ 雙因子理論:-工作滿意度-保健(薪資、環境..不給不行的)、激勵(不給沒關係、有更好,如升遷)
@馬斯洛需求理論 =需求層次理論
每個假說都有理論、文章、書籍做支撐你的想法,都要提出來寫清楚。
電子資源>CEPS>1.Airiti Library華藝線上圖書館
電子資源>SDOL >1.ScienceDirect (SDOL)
電子資源>EBSCO
主題、keyword +研究方法
@AHP/ANP 主要是做(找出)關鍵因素(vital few),
Open Access 開源
開放取用 [(Open Access) ](https://www.editage.com.tw/blog/research/what-are-the-differences-between-open-access-and-standard-subscription-based-publication.html) 和一般訂閱期刊的出版有何不同? @ 收費機制有爭議[MDPI 出版社](https://www.mdpi.com/) 全部Open Acess; 審查時間比較短; Sastanability Journal中原的企博、商博應該還可以投這個期刊。有些學校不同意。
Mathematics 什麼都收。收費貴。
• 知乎PCA(主成分分析)的理解與應用
• 知乎主成分分析法的基本原理就是一個示意圖,紅色的點是原始的二維數據,藍色的線是第一主成分,黑色的點是數據在第一主成分上的投影,也就是一維數據。
• 主成分分析(Principal Component Analysis, PCA)是一種統計方法,可以用來簡化數據集,減少數據的維度,並保留數據的主要特徵。一個簡單的例子是: 假設你有一組二維的數據點,每個數據點有兩個變量 x 和 y。你想用一個一維的數據來表示這些數據點,也就是用一個變量 z 來代替 x 和 y。你可以用 PCA 來找到一條直線,使得這些數據點在這條直線上的投影的變異數最大,也就是這條直線能夠最好地反映數據的分佈。然後你可以用這些數據點在這條直線上的投影的坐標作為 z 的值,這樣就完成了從二維到一維的降維過程。這條直線就是第一主成分,也就是數據的最主要的特徵。 • Medium成分分析的概念及應用
多變量分析是一種統計方法,可以用來同時分析多個變量之間的關係或特徵。例如,如果你想要研究學生的成績、智商、性別、年齡等變量如何影響他們的學習成就,你就可以用多變量分析來探索這些變量之間的相關性、差異性、因果性等。多變量分析有很多種方法,例如主成分分析、因素分析、聚類分析、判別分析等,每種方法都有不同的目的和假設。你可以根據你的研究問題和數據特徵來選擇合適的多變量分析方法。
Open Access Journals Toolkit。
| 特徵 | Open Access的Journal | 傳統的Journals |
|---|---|---|
| 閱覽費用 | 免費 | 付費或註冊 |
| 閱覽限制 | 無限制 | 有限制 |
| 再利用權限 | 寬鬆 | 嚴格 |
| 出版費用 | 由作者或機構支付 | 由讀者或機構支付 |
| 出版速度 | 較快 | 較慢 |
| 出版品質 | 可能參差不齊 | 一般較高 |
| 出版影響 | 可能較大 | 可能較小 |
洪哲文ACP: 應自己做個小專題研究-學期成績。 AHP-幹部spmp的選擇-儲運;內勤;董事長;
W02 多準則決策分析Multiple Criteria Decision Analysis(MCDA)
2024-02-27-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
1.Multiple Criteria Decision Aid, MCDA 概論
2.The Essence of Data 資料處理
*Australian BioCommons: The essence of data visualization in bioinformatics (Webinar) (60min.)
-
Page06.
一個(研究)系統(模型)不外乎IPO: Input-Process-Output
- I: User, Enviroment
- 參考: EKB Model of Consumer Behaviour 解釋消費者購買決策 (1968)
資料之所以產生價值,一定是經過「處理」process, miming..etc.。經過處理後,就成了企業的財富。
miming: 進階分析, 找出資料間的關係。Tools如AI,統計...。資料量不只是大,異質性
發現: 關聯規則-Association Rule-尿布+啤酒。->Apriori演算法。Layout plaining, Recommendation system.
中原大學-蒐集教授的研究paper做Text miming,查出他們的研究傾向。
論文要先做企劃書 prototype (圖形表達),通過後才開始寫。關於論文計畫的說明
(比如服務品質與客戶滿意度)「不顯著」不代表「不存在」。
要投稿-這是最好的訓練、建立信心最好的方法。看不見的Reviewer是最重要的推手。
- MADM多屬性決策(Multiple Attribute Decision Making)是一種基於多個評選準則,經由系統化架構以評估方案的方法,已被廣泛地用來解決方案排序的決策問題。 - 我們課程偏重,探索性研究Exploratory study。作為後續研究的基礎。Data Miming也是一種 Exploratory study,定性的分析、研究方法,也是。
- 內容效度Content validity (講得爾非法時還會再講一次)。問題跟題目相關性relevent高不高?
- 跟老師Meeting要有收穫的話,要預先做功課,才去討論。免得成為漫談。
- 資料取捨:比如要做旅遊預測,2020-2022年的資料可能需要略過。
- 為什麼做這個研究,總有個道理吧!把原因說好,把故事講清楚。不要陷在習慣領域Habiture domain 因為無論個人或組織,習慣後會趨於固定(熵增),所以員工需要學習、進修,以激活心智。或跨企業交流、研討。
- 人數少統計量就少,bias就增加
Page10.
- (通常)有高效度時,信度也不應會太差。
- 若要做CFA驗證性因素分析,可以用到「結構方程式模式」,
- 若要做EFA探索性因素分析,可以用到「主成分分析」:把很多繁瑣的細項整理為較少的重點項目。
Page11.
PCA is to avoid curse of dimensionality.
- 用較少的話,還能讓人清楚了解
。 - 做決策的時間很短,所以需要掌握重點,把原先的含意很快表達出來。
(見Page14.:- 多元共線性的問題舉例。y=C0+C1x1+C2x2 (若x1 x2相關性太高)會讓y難解釋,或奇怪的結果。等於把這個因素權重加倍。)
- Over fitting過度擬合: 只有教過的才會寫。只適合這個狀況,無普遍性。
- 訓練=建模。通常是為了預測之用。使用歷史數據去建模。比如股價預測。(查碩博士論文,很多人做。)
- Rolling-Window Analysis of Time-Series Models (林師模可能有教)Moving average
Page12.
- variance變異數。
- 線性回歸不會是預測工具,因只有單一一條線。 是作分類、切割用。Data Miming範疇就是分類、和預測兩類
Page .
Page .
W03 EFA/CFA and DEMATEL-sample of C國營企業
2024-03-05-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
1.Animation: AHP
2.: AHP Method
3.ゆっくり雑学 考察チャンネル: 定量的意思決定手法「AHP」を徹底解説!!【ゆっくり】迷える貴方に最適解を!
4.conceptualExploratory Factor Analysis (conceptual) | SEM Boot Camp 2018: Exploratory Factor Analysis EFA/CFA-for mdimention reduction (但是像性別、收入、年齡...等等非常明確,不屬於這種需要分析的factor)
5.跟著Jodus學SEM: 什麼是SEM模型 | 27. 結構方程模式(SEM)1_概念 | 28. 結構方程模式(SEM)2_單一構念 CFA | 29. 結構方程模式(SEM)3_整體CFA設定AMOS是只能在Windows桌面使用的,IBM的一款付費的結構方程建模軟體。
6.德菲調查法Delphi Survey | DELPHI PROCESSES OR METHODS德菲法 避免專家於面對面討論時,因特別強勢意見的存在,或面子問題,而無法達成共識的情況發生。
1.Hierarchical Decision Making 決策層級分析
2. AHP (Analytic Hierarchy Process, AHP)層級分析法
`
讀了胡老師po出來這篇Paper
(人力資源管理學報 第12卷第4期(2012年12月) 53-79頁)
- C 國營事業管理師與工程師皆為甄選
- 目前國內知名之衡量工具包含:1111 人力銀行評測中心之九大職能星、104 人力銀行職涯發展中心之性格量表、yes 123 求職網之哈理遜職涯評測(Harrison Assessments)等,皆有助於企業與求職者之媒合。
(九大職能星測驗施測與解說)、Harrison Assessment 哈理遜職涯評測是一種人才管理技術,它利用預測分析來幫助企業在招聘、發展、領導和參與人才方面做出決策。這項評測通過一系列問題來評估個人的工作偏好、興趣、態度和動機等多個與工作相關的特性,並將這些特性與成功完成工作所需的特定行為和能力相匹配
- 進行決策時,構面間與準則間大都具有相依性(即相互影響),網路程序分析法(Analytic Network Process, ANP)則適用於解決實務相依性之問題(Saaty, 2001)。ANP 主要是透過兩兩比 較之專家問卷,進而找出關鍵構面與關鍵準則,使企業將資源用於對的地方,同時,ANP 不僅具有 專為解決某一特定問題(於 ANP 中稱為「目標」[Goal])之特性(以本研究而言,即找出任職 管理師與工程師之人格特質),而且是整合專家群之看法,可避免甄選主管之個人偏好與強烈主觀, ANP可降低甄選主管之個人主觀性之影響。
- ANP可用於: 顧客關係管理(謝玲芬、黃婷筠、劉淑梅,2007;謝銘元、吳文明、王清德、陳敢東, 2009)、顧客滿意度、行銷企劃、品牌形象/品牌權益等,卻鮮少運用於人力招募與甄選,目前僅有黃宇晨與林谷鴻(2011)曾探討之,
- 本研究之目的為:
(1) 建構一評估架構,以作為員工甄選工具之一與進用之參考依據;
(2) 探討甄選管理師與工程師時之關鍵構面與關鍵準則;
(3) 探討管理師與工程師之綜合績效表現,
並進行排序,同時,與其之年度實際考績進行比較,進而探討其差異。
- 甄選工具之選擇,除效度外,尚需考量其公平性、可應用性、成本、取得難易、使用能力及可
接受程度等因素。
- 指出雇用前使用發展完備之人格測驗是促進社會正義和增加組織
生產力之方式。據此,本研究認為以人格測驗做為主要分析工具是具有其適切性
- 人格五因素理論(Five-Factor Model, FFM) 雖然在特質名稱上未完全一致,但大致能涵蓋評定成人之主要人格特質(Digman, 1990; Goldberg, 1990; McCrae & Costa, 1987)。
- 人格五因子
Fiske(1949) 社會適應 順從 實現 情緒控制 智力
Norman(1963) 外向性 親和性 嚴謹性 情緒 文化
Borgatta(1964) 自信 好感 責任感 情緒 智慧
Costa & McCrae(1985) 外向性 親和性 嚴謹性 神經質 開放性
Peabody & Goldberg(1989) 能力 愛 工作 影響 智力
Digman(1990) 外向性 友好承諾 實現意願 神經質 智力
資料來源:陳脈寬(2010);Carver 與 Scheier(1995)。
- Costa 與 McCrae(1985)提出五大人格特質,簡稱大五(Big Five),包含神經質(Neuroticism)、外向性(Extraversion)、開放性(Openness)、親和性(Agreeableness)、嚴謹(Conscientiousness)(定義如表 2 所示),其英文第一個字母連起來組成「OCEAN」一字,似也象徵其為能容納人格之「海洋」。
- 人格特質與工作績效之關聯
表 1 人格特質理論
表 2 五大人格特質之定義
表 3 NEO Five Factor Inventory(NEO-FFI)
- 研究方法: 修正德爾菲法(Modified Delphi Method)德爾菲法於第一階段調查時,須將整理過之決策問題之相關資訊與文獻提供予專家參考,再由專家提出解決問題之可行方案與評估該方案之準則。有效地簡化第一階段調查之步驟
- 網路分析程序法 多準則評估方法。,為解決各要素間非僅有單向(uni-directional)層級及獨立關係,而是以網路形式交互作用(interaction),如外部相依(outer dependence)、內部相依(inner dependence)、回饋(feedback)等關係,
- 步驟一:模型之建立與問題之架構/步驟二:成對比較矩陣及優先權向量/步驟三:建構超級矩陣/步驟四:決定關鍵因素
- 透過德爾菲法之匿名專家問卷,計算 CDI 值,以得知專家之共識度, (共識性差異指標(Consensus Deviation Index, CDI)之計算,進而得知專家團隊是否對每一準則已達共識。)
- 表 4 雛型架構
表 5 建構正式架構之專家團隊
- 專家問卷 根據表 7 與表 8 之關聯性,編製 ANP 問卷。填答者為新進管理師與新進工程師之直屬主管 - 表 6 管理師與工程師之正式評估架構
表 7 準則相依性(管理師)
表 8 準則相依性(工程師)
表 9 填答 ANP 問卷之專家團隊
表 10 研究對象之背景
- 效度分析 本研究之構面與準則是採用五因素人格理論中,Costa 與 McCrae(1992)所發展之五大人格特質量表(NEO-FFI),同時,正式架構是透過五位具有實務經驗之資深專家(如表 5 所示)所建構,因此,具有內容效度與專家效度。
- 構面之相對重要程度分析: 先,運用 Super Decisions 軟體以求得每位專家(如表 9 所示)之構面權重,並確認每一兩兩比較之矩陣符合 CI(Consistency Index)< 0.1 之要求,
- 準則之相對重要程度分析
- 表 11 構面排序(管理師
表 12 構面排序(工程師)
表 13 準則排序(管理師)
- 由表 14 可知,對於「工程師」而言,其前五名之準則排序為:我是一個快樂而歡欣的人(E3)
我很少感到恐懼或焦慮(N2) 我時常感到精力旺盛(E1) 我真的喜歡大部分我遇見的人(E2)
我通常盡力體貼和顧慮周到(A1)。
- 評估方案之績效表現
- 表 14 準則排序(工程師)
表 15 管理師之綜合績效值
表 16 管理師之工作績效考核
表 17 工程師之綜合績效值
表 18 工程師之工作績效考核
- 由表 17 與表 18 可知,「工 2」與「工 4」確實是表現最為優異,而其餘之表現較為不佳,其中,「工6」最需進行加強訓練,此外,主管認為「工 3」之表現應屬有待加強,然而,於 2010 年度考核中,卻排序為第 3,顯然其之實際表現並非太差。
- 準則 於甄選「管理師」時,關鍵準則為
- 評估方案之績效值
- 貢獻/研究限制與未來研究方向
-
- 請簡介: 應用決策實驗室分析法(DEMATEL)
。 - 注意: 要準備一篇投稿期刊論文(期末要交)
- P.9 加了幾個字:(題項與潛在變數間的關聯度), 另加一張slide「因素分析」(有照相)
- 做驗證性研究的第一部,先設計各種「構念」(參見p.6-研究架構圖)
p.10-2
- EFA發展量表 Exploratary Factor Analysis,在眾多的題項中,找出共同的潛在變數latent variable)。
- CFA驗證構念間的關係 - Confirmatory Factor Analysis 構念間的相互影響就是Strucure Model,構念與觀察變項的關係叫
做mesurement model。要做CFA 使用「結構方程模式」大概跑不掉。要驗證:合不合理,適不適配。
因素分析(補充/重作)
- 因素負荷,就是要做歸類用。把題項那一行-同一因子的數字最大的,歸為同類。這樣可以找出「因子」=「潛在變數」。
- 主成份分析,就是想「簡而言之」用最少的幾個因素進行說明而不失真。
-p.12-2
- Principle Conponent Anaysis
- 資訊保留(用較少的因子)去解釋,所以% of variance最高的是最重要的,所以1~13項中,比如取前60%就可以算是rough的主成份了。
-p.13-1
- 變數選邊站後,最後就是幫各個「因素」命名(因素一二三四 看其內容來做命名的基礎)
- @跟我教張振明,做選倉管大副的條件過程一樣
-p.13-2
- 原來有5個變數:
- 最後被歸納成2個因素: 你看他最後怎樣取名:p.14-1
(蕃茄應被歸類為水果還是蔬菜?小學考試-??)
- 小心若「變數高度相關」會是「共線性高」
- Model1: y=C0+C1X1 (這是回歸); 相關性太高就不適合放在一起,無論正或負相關。
- 自變數之間不該有高度相關; 應彼此分離/保持距離-應當相互獨立; independet variable一多時,就要小心。 如果太多的話,不妨用PCA把他濃縮成少數幾個,以免發生共線性。
-p.14-2
- 剛才是討論變數variable,這裡要分群是針對 資料data
- 人最多只能想到3度空間,書上多是用到2度空間。clustering anaylis就是要把data分群。分幾群通常要 try and error 試試看分幾群會比較說得通,比較能解釋。
- 可先設定3群,再一步步擴充或研究。
- 這是「讓資料選邊站」(之前的PCA是「讓變數選邊站」變數的集群,PCA像老大、精神領袖一樣)
- 超市每筆交易資料就是個觀察值,一個data。
- -p.15-1
- 每個 ○ 代表每一個學生。分好群後,可以幫每個群取個名字。
- 同質性homogenity 異質性heterogeneity
-p.15-2
- 市場區隔、目標選定、與定位方法。
-p.16-1
- k-Means 非常出名與重要的方法。了解他的概念。
- k 是多少,是我們自己設的,比如2就叫做2-means。若3就叫3-means。
- 分群,再找出群中心。每一群都有一中心。
- 每一點對自己的群中心接近(歐基里德距離最小),對其他群中心遠。
- -p.16-2
- 1.隨機. 2.分配-完了以後,重新算群中心。然後回到2.重分配。 若無改變則停止(穩定了)。若有人叛逃,就要去做3.更新-重新算群中心。
- 穩定後要為群命名,這一直是多變量分析的重要事:怎樣勾勒出形象,的合理的名稱。
- 對p.17-2 這種群是無能為力的。各種辦法都有罩門,有其限制。
-p.18-1
- 人是有限理性的。
- 捷思法 heuristics
捷思法的優點是可以節省時間和資源,減少計算和分析的複雜度,提高創造力和靈活性,適應不確定和變化的情境。捷思法的缺點是可能導致誤差和偏見,忽略重要的資訊和因素,過度簡化問題和解決方案,失去準確性和客觀性。
捷思法有很多種類,例如:
• 代表性捷思法(Representativeness Heuristic):是指根據事物與母體或過程的相似程度來判斷其機率或歸屬的方法https://zh.wikipedia.org/wiki/%E5%90%AF%E5%8F%91%E6%B3%95。 • 可得性捷思法(Availability Heuristic):是指根據腦海中直接浮現的例子或資訊來判斷事物的頻率或重要性的方法。 • 試誤學習(Trial and Error):是指通過不斷的嘗試和錯誤來找到問題的解決方案的方。 • 啟發式演算法(Heuristic Algorithm):是指在電腦科學和數學中,用來解決複雜或無法保證最佳解的問題的一種近似算法。
- 逛了一下午,沒找到滿意的,又不甘心白走一趟,隨面買了一件。 這叫「沉沒成本Sink cost」是決策陷阱的一種。
- Decision myyopia, Anchoring, Framming effect, Sink cost, Groupthinking, 有一堆 「決策陷阱」
p.20-1
- 得到諾貝爾獎的 三階段決策過程。Simon's three-phase model of decision making.(Simon's problem solving model ) Simon model -Herbert Alexander Simon
- 1-Intelligence收集資訊. 2-Design發展與評估方案. 3.Choice選擇執行方案。
- 關鍵因素:權重相對比較大的因素。8-2法則,企業資源應用在少數而有影響力的關鍵因素上。
- 要找出因果關係時,用的就是決策實驗室分析法(DEMATEL)。
- 決定權重可用AHP與ANP法。
- 本課程重點在 「賦予準則權重」 和 「找出因果關係」上。且萬事起頭難,最重要的就是第一步的工作,架構沒弄好、文獻不適當,接下來的工作就不可靠。
p.20-2
- 時間到了就該做決定,只能是盡可能的得到令人滿意的決策,而非「最佳」的決策
- 決策者無法鉅細靡遺處理任何情境的因素或資料,而是簡化,只能去思考少數相關與重要的因素去做成決策。
p.22-1
- 多準則績效評估 (我們的課程重點從這裡開始了) w1 w2 w3 是權重。
- 簡單的加權平均法,就可以做出好的決策。
- 準則(科目)有權重,方案(考生)有總分。分數或稱績效值。
- 若無權重(就叫nondominated) 看起來各擅勝場,委實難分高下。
- 這學期教的都是在 權重總和為1的情況下計算。
- Jacky說: 他們鴻海工作方法是 collection-divided-conquer 三步驟。
老師說 還要看趨勢、(時間季節).隨機性..等各種因素要分解、以上就是。Divide and Conquer。比如分解不同區段,去研究,最後再合成起來。
- 找出各種method通常各有 優劣,怎樣抉擇在乎決策者。這裡只是提供決策備選。
W04 MCDA (Multiple Criteria Decision Analysis)
2024-03-12-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
Principles And Operation of Analytic Hierarchy Process, AHP
1.創知堂の日常閑話: 複数の候補の中から合理的に選択していくためのAHPというやり方について解説しました。
2.「巨大數據」的1hr課程:
質性研究: 訪談+文獻+觀察(三角驗證) -第3章開始分家
量化研究論文:包括四類:描述/相關/解釋/差異性研究
台灣汽車保養廠-描述性研究。
Rsquare>0.3就很好啦 社會科學,有太多變數可能發生
解釋性: beta/p value/Rsquare
就是研究變數的(Mean, SD, r, beta, p)5個元素
p.21-1
MCDA多準則決策分析 Multiple Criteria Decision Analysis
MCDA refers to methods for decision making in a dynamic environment in which multiple, often conflicting criteria (ie. multiple attributes or objectives) must be taken into consideration.
MCDA can be roughly separated into Multi-Criteria objective Decision Making (MODM) and Multi-Attibute Decision Making (MADM).
有另開「資料包絡分析」Data Envelope Analysis (DEA)做績效評估的, 評比的。很成熟的方法。可作公司間比較、跨產業比較。做 產出/投入 。這樣的文章很容易發表
* MODM: Plan and design problems with multiple objectives based on a decision space 這是focus在Objective 目標式不外乎「成本 或 利潤」。大學部課程講OR講單一目標single objective,多目標到研究所來講。
為達目標就須投入資源,但企業資源有限制(限制式)需要考慮。Resource Allocation. 人力、倉儲、車輛...客戶要求,競爭對手..等Xn項
MODM有軟體叫LINGO 或 LINDO較麻煩,須下語法。比如寫:目標是什麼?限制是什麼? (LINDO/LINGO 作業研究軟體)
若可做出二維圖圍出一個可行解區,5個交點中,應有一個可行解在其中,試算看看就可知道,這就是在找關鍵因素。
* MADM: Evaluate and select alternatives, including weight analysis.
p.21-2
決策矩陣 Decision Matrix or evaluation matrix, performance matrix, impact matrix...)
方案Alternative 準則Criteria 綜合績效質(總分)加權平均法 Synthetic performance
p.22-1
多準則績效評估 如何使用加權平均法?如何計算縱合績效值?
總分沒有出來,就很難抉擇(看來大家各有各好,看來都一樣的好),一但有了總分,高下立判。
* 5個準則,如果權重相等,各個權重= 1/5=0.2 (權重加總=1)
比如Fran如果這樣算是錯的 (0.2x650+0.2x4.0+0.2x6+0.2x9+0.2x8) 因高分影響太大
* Which one is the benefit attribute? cost attribute? 要這樣考慮:
1.各個分數是benifit考慮,就是越大表示越好。 如果各項總分不同,要先做 normalization
介紹這本書: Yoon, P.
p.23-1
多準則決策的內涵 游伯龍提出
習慣領域(Habitual Domains)理論是美國堪薩斯大學商學院的游伯龍(po-Lung.yu)
- 準則之間,以權重比高下。權重越大重要性越高。
- 方案比較, 總分越大,勝出、被選擇的機率(可能性)就越高。
p.23-1
多準則決策的內涵 (Cont.) - 跟決策直間接相關的叫information不相關的只是data
p.23-2
- 中間的DM 是Decision Making
- 還包括了Allowable time. 有限的時間
- 有限理性、三階段 納進來
- 游伯龍(po-Lung.yu)交大終身講座教授
p.24-1
屬性 vs. 目標 屬性和準則都混在一起了,似乎還有點差異
- 屬性是沒有方向性的
- 目標objective決策者感認較佳的方向, 滿意的標準 Aspiration level, 標的goal依需求事先決定的特定值
p.24-2
績效評估指標的特性 The criteria are often conflicting (competing, trade-off) and non-commensurable (qualitative/quantitative, measurement units, and cost/benefit).
1.定性與定量指標存
2.指標的計量單位不同
- 定性指標如何評估,最好的方法就是likelihood scale似然指標
p.25-1
3.評估準則的偏好方向不同: 望大型benefit attributes 望小型cost attributes 望目型 nonmonotonic attributes夠用就好,合適就好
- 體檢指標應該都是「望目型」。
p.25-2
定量屬性
- utility 效用
- such as: Fuel efficiency, Production cost, Blood sugar level in a human body.
p.26-1
正規化
To obtain comparable scales, attribute ratings should be normalized to eliminate computational problems caused by differing measurement units.
- normalized value should be within 0 to 1.
- The higher, the better 高利潤 or 低成本, 正規劃值越大;
- 正規化之後的質,就代表一個偏好度(喜歡的程度)。最高是1最低是0。
- The higher, the worse比較少用,因為不直覺。
- 以P22-2為例:GRE 希望700為1; Collage rating則希望10為1;
p.26-2
望大型屬性正規化 - (a) 只要把最大的數值當分母,就可求出各個normalization number.
- (b) 用差數做比率(分母是 max-min),這樣可以把距離拉得開一點(分子是 自己-min)。
p.27-1
望小型屬性正規化 - (a) 讓自己當分母, 最小數當分子。就可算出來了。
- (b) 分母是max-min, 分子是 max-自己。
(像資格考就是考這些,主要是判斷望大還是望小 別搞錯,公式會給你但判斷要對,考試是open book)
The main purpose is to make everybody to be comparable scale.
p.27-2
望目型屬性正規化 - 先選出desired number.越靠近此數正規化值越靠近1。越遠越靠近0
- (a) r ij=min{42, 44} / max{42, 44} = 42/44 = 0.955
- (b) r ij=1 - | 42-44 | / max{50-44, 44-42 } = 1-(2/6) =2/3=0.667
注意讀每個數字符號的定義
公式用對了,都是1最好,0最差,把數字加起來,結果就出來。
W05 Analytic Hierarchy Process (AHP)2
2024-03-19-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
Application of Analytic Hierarchy Process (AHP) on the management decision
(運動會 停課)
W06 EFA vs. CFA (PCA)
2024-03-26-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
決策分析軟體 (Expert Choice)實例操作
p.28-1
問題與解決方法-多準則決策之重要度與績效值分析:
I.往往花最多時間。II.因素分析PCA化繁為簡,EFA或CFA,我們探討EFA多。特別PCA。
III.明式結構法ISM和DEMTEL都是找因果關係的方法。(探索性EFA和驗證性CFA研究是不同的 )。IV.企業常要找關鍵準則(20/80):AHP/ANP/DEMATEL。
V.績效評估方案評選(這次課程不會講,可以自己去研究 去看Literature Reivew of 什麼什麼 大約就是這類的.),胡老師是學管理的,說:管理有二學門,管一學門和,管理二學門各領域(包括資訊管理、行銷管理、生產與作業管理)
管理學門目前在國科會分成管理一與管理二兩個學門兩個學門,主要依企業功能來區分。
VI. 國科會 TSSCI 國際期刊 。"管一"可能指的是一般管理學門,涵蓋如財務管理、人力資源管理、策略管理等傳統管理學科。而"管二"則可能專指資訊管理、行銷管理、生產與作業管理等較為專門的管理學科。
VII.更進階 跟AI有關,講預測:時間序列, 經濟模型, AI, Judgement method。
p.28-2
問題與解決方法(Cont): In the field of MCDM, many utility-elicitation methods have been developed to model a decision maker's multi-attribute utility (MAU) function.
Input - Process - Output
holistic approach : a decision maker is asked to provide the overall evaluations of alternatives. 多元回歸就是一種holistic (f:就是想找出這個函數 x:input y:output) 比如股價預測、來旅遊人數預測,都可用歷史數據做自變數應變數,找出P(因I和O都知道)。這就是一個建模的過程。y=c0+c1x1+c2x2 要找出c0, c1, c2的過程。
但比如做 兩岸學生交換數預測、來台遊客預測,碰到covic19這三年的數據要特殊處理。
decomposed approach : 和holistic正好相反,參數都是受訪者告訴我的。所以要發問卷細細問就是,這是I和P已知,要去求出(推估出)O。請看P22-1 Sample就是典型的decompose 總分是最後才知道的。(P就是加權平均法),兩者都是建模,(求P和求O)方法不同。
常用工具如SPSS,(神經網路也是一種工具稱為非線性工具,序列是震盪的比如去日本旅遊的人數變化可能受季節、活動..因素影響)
線性回歸通常用來做自變數的篩選,實務上不會拿來作預測,因他只有一條線。
p.29-1
AHP 層級分析法 使用層級架構決定關鍵因素:目標-構面-準則-方案
住宅選擇 Example就是這四項。 (Analytic Hirachy Process) 。
p.29-2
ANP 網路程序分析法 使用網路圖決定關鍵因素: Analytic Network Process
a 影響到b 的網路圖,先將網路圖畫出來,再來找出影響的關係與權重。這圖就像是個研究架構
Saaty 提出的(不是Satty)
p.30-1
IPA 重要度/績效度分析:
對某企業或組織,做績效分析時使用。每個三角形都是一個準則。
Quadrant II可能是資源措置。 這方法對於發展出策略有幫助。
橫線取法-1/2或1/3主要是 關鍵因素不應是太多。 比如地勤無法留人:想研究離職/留任的IPA
績效值可用Likelihood量表,發問卷調查。
第5章是戰場,第章是 p.30-2 - 33
民宿經營之關鍵因素: 小半天民宿怎樣把(過路)客人留下來
不能說我是這媳婦所以研究,要說研究這個可以解決什麼問題?改善什麼成果。
這裡就用到IPA
p.34-1
IPA 關鍵因素間之因果圖: 為的要做源頭管理、想找出源頭
32-2 發展準則時,去問經營者和消費者。
可找這篇論文來參考。
p.34-1/37-1
烘培師傅於國際競賽獲獎之關鍵因素:
國際資訊接軌能力=領導者的能力,領隊。
萬事起頭難,成員怎麼產生的。這樣論文的參考文獻比較少,所以就找參考的(其他競賽的)文獻
@這或可作為我們公司:要開發某種(如食品級)潤滑油的市場成功關鍵因素
p.37-2
多屬性決策分析模式的選擇: Whick method is appropriate to the problem?
你問什麼?想知道什麼?
p.38-1/2
德爾菲法 Delphi Technique:
這是用書面問專家的看法,不是holistic也不是decomposed method。
@問卷調查:用foadpanda或uber eat點午餐選擇的要點、準則,每個小姐都是專家。可以請教他們的觀點和意見。可用Delphi法,透過多次反覆期能達成共識找出因素。
開始進行後,可能有人離開,但無法讓人再加進來。
第一回合最重要,也是最麻煩的(比其其他回合),
有內容效度Content Validity
p.39-1/2
特點(Cont):
匿名進行:這和腦力激盪法完全相反
回饋控制feedback control
共識達成 Consensus 德爾菲法目的在於共識的達成。
- 共識會用到標準差、平均值: 這兩個數字對樣本數敏感,若太少數字會不可靠。樣本多多益善,至少也要10以上
- 四分位: (第2四分位就是中位數) 大致有25%落在第1四分位之前和第3四分位之後。數值需要排序。四分位會忽略不同的意見,這是優點也是缺點。
林億雯2021碩士論文 新冠疫情下影響餐飲業微型創業之關鍵因素
科技管理學刊2022Paper 新冠疫情下影響餐飲業微型創業之多準則評估
1. 應用AHP探討消費者選擇餐飲外送平台之關鍵因素:這篇論文通過層級分析法(AHP)來探討消費者在選擇餐飲外送平台時考慮的關鍵因素,發現「食品安全與衛生」、「品質」、「便利性」和「價格」是消費者最關心的因素。
2. Exploring the key success factors of Taiwan's food delivery platform:這篇研究探討了台灣餐飲外送平台成功的關鍵因素,包括服務品質和消費者購買意願等。
3. An Empirical Analysis of E-commerce Operation Model-Taking an E-commerce Merchant as an Example:這篇論文以一家電子商務商家為例,進行了實證分析,探討了電子商務運營模式。
4. 外卖平台决策研究:這篇文章基於外賣平台的經營現狀,探討了外賣困境問題的產生原因,並提出了相關政策建議。
5. 蔡翼擎 AHP探討台灣餐飲外送平台如何建構競爭優勢之關鍵決策因子 6. 20230224工商時報外送大調查 兩大龍頭常用度差距縮小
7. 20201126商業經營foodpanda、Uber Eats在窮忙?台灣餐飲外送白熱化,4大關鍵情報看懂產業版圖
8. 20230111《商業周刊》第1835期熊貓700億稱霸解密!爭議多,憑什麼終結虧損、市占第一
9. 20240223新零售台灣外送平台大調查:foodpanda、Uber Eats策略差異化,45歲成分水嶺!
客人:客人想吃什麼、愛吃什麼?可接受的價位?
埰購:穩定貨源?品質:養殖、冷凍、生猛。蔬食
員工:有技術的員工、穩定持續工作
行銷:1.Line官網+私網(600(300)) 2.短視頻缺 3.Youtube缺 4.老顧客、管理層以上者須新增
W07 Modified Delphi
2024-04-02-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
網路分析程序法 (Analytic Network Process, ANP)
1.Analytic Network Process, ANP
2. Network Relationship Maps
3.AI: 紹介します
p.39-1/2
德爾菲法 4個特點 :
最重要就是要達成共識。(有時也可能難以達成全部共識,此時也可以不用強求。)收斂=達成共識的意思。找專家同溫層的最好在七成以下,找真的會認真給意見的人,願意幫忙(參與)到底的人。
Round1-通常是值性,旨在建立概念,不評分。Round2起開始評分。通常頂多作到Round4就該收斂了。
p.40-2
修正德爾菲法(Modified Delphi):
先參考文獻整理出架構,在開始跟專家討論,這樣比較有效率。
p.41-1/2
員工留任因素的研究:
準則=項目。 參考p.42 修改後的結果。
找關鍵因素的話:就會變成「重要程度」。
若是「必要性」判斷必不必要,就是要判斷與主題的相關性。
所以說DEMATEL法,可以用來決定「必要性」也可以用來判斷「重要程度」。用途很廣、端在語意的變化。
p.42-2
共識的達成-共識性差異指標:
當數據進來後就會產生標準差。
平均值和標準差。
這本書:鄧振源多準則決策分析:方法與應用請參考
p.43
以興建廠房為例-問卷分析:
鄧振源書中的案例。
Round1.不脫離甲乙丙丁戊地。 關鍵因素找重要性。把全部準則那進來。
Round2-標準差 STDEV 可用excel跑出來。CDI= STDEV/max. Mean (Clustering Deviation Index) 希望是在0.1以下。
共識沒有形成,便得做下一次。(為要找出feasible可行方案)。此時應提供看法與眾不同者(CDI高者),與其溝通或提供其他人的意見供參考,而不是急著立刻再發一次問卷。
溝通對象: (Mean +- Sigma) 以外者。
(已請佩文盡快買鄧振源的書來看-研究參考)
P.44: 請看風水項:平均是26.83 +STDEV 22 = 48,而專家3打出70分高出甚多,需要溝通,請其考慮修改。
看P.45這個同學的設計不錯,他暗示「您」的意見和別人相差是否太大。請專家再次斟酌。
鄧的書每次都重新評分,其實沒必要,只要針對未達共識的項目重作就可。
不成熟的、未來的、想像的叫不易達成共識,比如「未來汽車的發展」。
p.48-1
達成共識 選取可行方案-是高層決策者的工作:
這是從主管的看法中,做出客觀的評估,找出決定關鍵因素,已作為決策參考。
由14個準則中,找出5個特別重要的「關鍵因素」。(5個只是舉例,總之關線因素項目當然不該小於項目數的50%)
胡老師推薦,鄧書講CDI講得很清楚,足供參閱。
p.49-1
四分位距 Interquartile range, IQR:
IQR不受極值干擾,數字越小代表多數的資料越集中。表示重視的是主流意見。過高或過低-不重視、無所謂。但「失」的也可能是有價值的不同意見。
但如果樣本數太少(比如小於10)結果就容易受到雜訊干擾。
(操作上 看你是要用CDI 還是用IQR 各有利弊,但用IQR比較容易收斂)
偏重在一致性看法的探討,但如果有發現極值(看法與眾不同的人)也該去問,去了解。
老師作為reviewer會問: 請問你用Fuzzy AHP做,和只用AHP有何不一樣? 要複雜要有原因,有道理,不然做Fuzzy做什麼?
複雜要有複雜的代價,不然你作得那複雜要做什麼?
W08 Reaching Consensus
2024-04-09-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
1.Application of Analytic Network Process (ANP) on the management decision
2.Issues of Conformity with Multi-variable technology and ANP
助教說* 下學年將無夜間課程。 (不然就得要開在週末假日了)
p.49/2
Topic:
QD=1/2 IQR。 Q1-Q3 之間就是一半的意見,主流意見majority。 但若CDI 過大,就該去關注他們的意見。CDI= STDEV/max. Mean (Clustering Deviation Index) 希望是在0.1以下。
p.50 -2
複習四分位距 的計算範例:
四分位差(Quartile Deviation, QD)的計算公式是 ( QD = \frac{Q3 - Q1}{2} ),其中 ( Q3 ) 是第三個四分位數,( Q1 ) 是第一個四分位數。
四分位差是IQR(Interquartile Range)的一半。IQR是第三個四分位數 ( Q3 ) 與第一個四分位數 ( Q1 ) 的差,即 ( IQR = Q3 - Q1 )。因此,四分位差 ( QD ) 是IQR的一半,用於表示數據集中間50%的數據分散程度。
。
p.52 -1
共識的達成 四分位差:
請看 他們用了6分制的Likert-type 李克特表,打分數。
p.52-2
他在Round3就直接發出問卷,但是:請看modems這題,缺乏可能會行成網路教學的障礙(當時網路不發達、modem很貴) 。他給問卷時,2x prior rating試題醒受訪者說,你的看法和大部份意見(4,5)是不同的。用這樣方法在告訴受訪者,而不是逐一去溝通。
就是他用(代表Q1,用)代表Q3。
請注意However所說: If hte new rating was ourtside the IQR, the pannel member was asked to provide a reason for deviating from the majority of the pannel.
。
p.53 -2
第一次評分:
注意,值3是未達共識的意思。要去關懷、去蒐集意見,了解原因。
p.54 -1/2
第三回合:
這是從p.52-2這張問卷 改良過來的。這樣的設計會比較好吧!
當然原因若能能事先收集的話,也很好。
p.55 -2
決定關鍵因素:
@P.55-2或可作為 買卡車判斷因素-關鍵因素-參考。
決策分析的三階段論:Delphi -> AHP 或Delphi -> DEMATEL -> AHP
所以通常都要從Delphi開始,把問卷的架構先確認下來(主題、準則的「必要性」確定下來),才能進行下面的調查、分析。
p.56 -1
研究架構的評分問卷設計:
不管做什麼研究都不該違背常理,若違背就該檢討問題。
p.50 -2
穩定度 Stability 幾回合下來,達成共識的題項應該是越來越多。然而,也有可能有些項目始終無法達成共識,但他們的回應是穩定的(即不願更改評分,分數問定,不會再變來變去了)。
穩定度通常配合共識度考量,總不能沒完沒了的問下去。
p.57 -1/2
穩定度 計算:
net person-changes 改變意見(改變評分)的淨人數 / 參與評分者總人數。
低於15%為穩定,所以如果共有10人評分,少於2人改變意見的話,就穩定了。
注意:Total changes指的是分數的變化,不是改變意見的人數net person-changes。
p.58 -1
這兩個學者是這樣做決定的,請看他們的說明。
共識度>70% 且穩定度也 >70%所以,他們的Delphi process就在這兒打住了。(這些項目會保留,而且往往收的反饋不同意見也比較多)
p.58 -1
數據分析 範例 high or moderate 都是已達共識
數據分析
* Discussion focuses on high consensus items that were either very likely or very likely to oceur, selected moderate- and no-consensus items are discussed as well.
* To further understand items that did not reach consensus or attained only mo
consensus, a summary of panel members' comments is included.
* Because panel members were requested to provide a reason for their deviation from the majority of the panel very few comments were received for items that reached high consensus.
數據分析-範例(Cont.)
Example
Holden and Wedman (1993) predicted which computer mediated communication (CMC,電腦中介傳播) applications will become prevalent, the resources required to support these applications, and the major obstacles that will need to be overcome.
* As a way to facilitate comparisons among items, numeric ratings were next grouped by dividing the sum of the scale values by the number of ratings.
* For the purpose of discussion, the medians (Q2) of the Delphi items were subjectively translated into various categories of likelihood of occurrence.
< 2.00: very unlikely to occur; low priority
2.00 and < 3.50: unlikely to occur; moderate priority
= 3.50 and < 5.00: likely to occur, high priority
= 5.00: very likely to occur; highest priority
Holdeu, M. C., Wedman, J. F. (1993), Future issues of computer-mediated communication: The results of a Deiphi study, Educational Technology-Researchi and Development, Vol. 41, No. 4, pp. 5-24.
高共識度的項目,意見往往較少。共識度低的意見反而多。但專家意見即使雜音多,也定要忠實呈現。
注意他的分數的切法設計。
p.58 -59
數據分析 的範例:
CMC 是當時研究Computer Media Communication 未來運用電腦做溝通的研究
看那些moderate 和no consensus 的題項、意見特別多。
像Distribution of class greads via e-mail 中位數是5.1 但QD是 1
。
接著跳過去講 p.89 (右下p.165)
p.xx -1/2
明示結構法 Interpretive Structural Modeling:
- 元素多、期間互動關係多,這些直間關係造成的複雜度高,令人難以清楚掌握。
A -> B -> C 或謂 A ...> C 間接影響了C。
ISM 就是 找出(明示)這些(元素的)結構關係的方法
p.90 -1/2
有向圖 Directed graph = Digraph:
可以交互關係用 圈、點、箭頭..表示出 interdependencies 交互關係。
p.90 -/2
6個頂點所構成的有向圖:
vertext(element) edge(relation)。呈現的是誰影響到誰。
比如從(1)(2)(4)可以到達 (3) 這是Reachable。
而(2) 和(3) 及(4) 和(5) 是鄰接的關係。
矩陣 直行column 橫列row (台灣和中國正好行列翻譯顛倒),行數與列數相等謂方陣。
鄰接矩陣 0表無影響 1表有影響。此表格數據可透過發問卷方式建立直接影響關係矩陣。
但間接影響需用數學方式去推導出來。
p.91 -1/2
有向圖 層級架構:
ISM會將 鄰接矩陣轉換為層級架構 (網路圖) 來呈現出來。
p.90 -1/2
:
。
p.90 -1/2
:
。
作者序
多準則決策(Multiple Critria Decisio Making)已成為現代公共部門重要的功能,應用的領域也非常的廣泛,諸如投資規劃、策略規劃、財務規劃、預算規劃、區域規劃、能源規劃、區位規劃、運規劃、港埠規劃、設施規劃、水資源規劃、防災規劃、人力規劃、警政規劃、產品規劃、生產規、排程規、休閒規劃、生涯規劃、軍事規劃、需求規劃、都市計劃、土木計劃、銷計劃、採購計劃、配送計劃、研發計劃、行政管理、科技管理、品質管理、績效管理、環境管理、及其他相關的領域。
計畫評估的歷史,溯自二次世界大戰以前,但大都強調財務方面的衡量取捨分析(trade-off analysis,後著重在成本效能原則(cost-effectiveness principles)應用。二次世界大戰後,成本效益分析(cost-benefit analysis)的應用日漸增加,在1970年代以前已成為評估的重要工具。在1960年代末期,多準則評估(Multicritirea evaluation)的研究開始萌芽。逮至1990年代後,整個多準則決策(Miltiple critirea decision making: MCDM)的理論愈臻熟,實務應用也日漸增加,並逐漸成為主要的評估工具。
本書主要介紹計畫評估的方法,包括MCDM領域的AHP法、多準評分方法、定多準則評估法、性多評估法、化量化多準則評估法、優勢,總共三十餘種評估法。為使讀者易於瞭解各種評估方法的内及求解程序,本書以step by step的方式,利用解釋例詳細說明與分析。本書總共包含六十餘個例題,用以解析所介紹的各種方法。
本書在國内有關多準則決策(MCDM)的專書中,屬於第一本詳細介紹多準則評估法的工具書,同時也是第一本介紹方案評估的方法論著。多準則評估技巧不斷地發展,有些已與模糊集理論(fuzzy sets theory)相結合,未來將繼續努力整理這方面的評估法。本書的完成,有許多人貢獻出他(她)們的心力及勞力,在此致上由衷地感激。
于大山華梵大學運籌管理暨決策析研究室
鄧振源2012年9月
W09 ISM (Interpretive Structural Modelling)
2024-04-16-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
決策分析軟體 (Super Decision) 實例操作
Youtube Interpretive Structural Modeling ISM in one click using SmartISM
Youtube Interpretive Structural Modelling-Simple Example- Dr. Rahul Mohare
MCDM是一種涉及多個衝突準則的決策分析子學科,它評估在決策過程中多個相互衝突的準則。MCDM包含了多種工具和方法,可以應用於從財務到工程設計等不同領域。
因此,ISM作為一種結構化的方法,可以幫助決策者在考慮多個準則時,理解元素之間的關係,這與MCDM的目標是一致的。所以,我們可以說ISM是MCDM方法的一種。
p.91 -1/2
層級架構:
activity-on-node (AON) 每個note表示一個活動
activity-on-arc
SCI 任何人看到這文章,可以照樣複製。若是管理類的,重視管理內涵,或分析手法。這兩種的重點不一樣。
。
p.92 -1/2
明示結構法-從屬關係:
Main puroose is to decompose a complicated system into a hierachical structure.
架構 a->b 網路圖
關係分為direct indirect兩類。
subordination 從屬關係 [1] elements & relations (此處elements = factors)
[2] subordiantion / Experts
[3] Encode the relationship
文章都是來自paper: Warfueld J.N.
。
p.93 -1/2
鄰接矩陣 Ajacency matrix:
- It represents a binary relation between a pair of finite sets.
- The entry eij in the ith row and jth column reflects the subordination relation between elements i and j from the set of elements. If element i is subordiante to element j. the entry eij will be one; otherwose, it will be zero.
- Example
要自己練習矩陣運算
。
:
p.93-2[Example]
- 受訪者決定鄰接矩陣(填問卷)。(請注意單箭頭 或雙箭頭的意思)
---以上是受訪者提供資料,以下是運算的作業-----
- 已關聯矩陣(connection matrix)顯示因素間是否可直接(一步)到達。
關聯矩陣= 鄰接矩陣 + 單位矩陣
(單位矩陣: 就是自己會影響自己=把左上到右下的對角線元素全部填為1 其餘都為0的方陣)
直接影響靠問卷,間接影響靠excel。
p.94 -1/2
直間接影響:
你會發現有些路徑是:透過兩步產生影響的可能。
b->a->a 看右圖: baa, bba是可能的, 但bca或bda不可能(因中間有個0)
**直接影響關係建議使用Linkert 4-point scale。(因為: )
- 一個元素可否透過兩步影響另一因素,可以用方陣乘法算出來。
- 這是探求間接影響關係的數學方法。
p.95 -1/2
直間接影響(Cont.):
- N^2 是否兩步可達-直間接影響的幾何意含。
- N^k = N^k+1 時,稱為可達矩陣 reachablility matrix
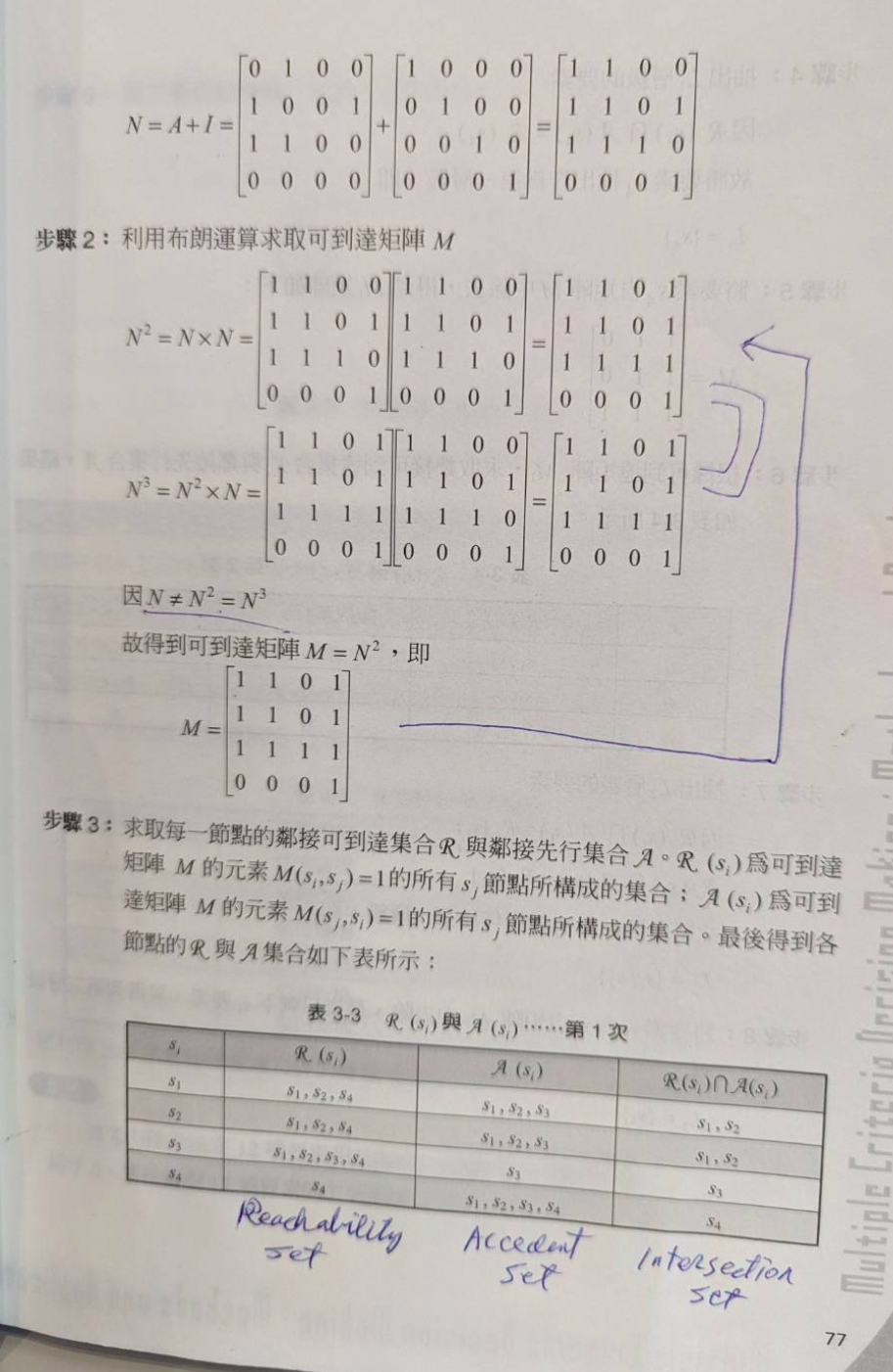
[Example] 當 N^2 = N^3 時可以停下來了。不用繼續做了。 。
- 鄧振源 書:多準則決策分析 方法與應用
- 關於英文論文: 可請ISE幫忙潤稿 以前用李國鼎基金會, 後來有華勒思,學校也有輔導的單位。
p.95 -2
發展層級關係:
由可達集合 (adjancency reachability 看列 我會影響誰)與先行集合(adjanceycy antecedent set 看行 有那些可以影響我) 決定屬於同一層級。
- The reachability set consists of the factor itself and the other factor that it may impact, whereas the antecedent set consists of the factor itself and the other factor that may impact it.
- 請再研究這個發展過程 lafder digraph [試著自己看矩陣畫圖看看]
- simpler form of hierachy (不考慮畫階層)
。
p.96+
老師多給一張專案管理:
- 專案里程碑Milestone專案中的重要時點 或 甘特圖Gantt chart-控管時間
- alpha test在實驗室測試模擬資料測試, 市場上測試beta test找志願者
Top- & Bottom-Level Sets:
- 若發現某列全部是0 這個肯定是Top-level set (因為他都沒有箭頭出去呀)(是結果)
- 反之若某行全部都是0 這可能就是bottom-level set (是源頭)
請看 鄧振源書p.79, p.82
目標-構念-準則(三層)鄧老師用ISM的方法來建構出來。
。
p.99 -1/2
Driving & Dependence Power:
- Driving影響別人 和 Dependence被別人影響的力量
- Driving就是 列和(把列的數字相加) 列就是我去影響別人
- Dependence 行和(把行的數字相加) 行就是我被別人影響
- 淨效果 Net Effect = 列和 - 行和
Accedent是初因,set是可以去影響他人者的集合。
尤其我要請假去日本,一定要自己學習好。
自己回去做好,下週對答案!
問: Waht is the form of hierarchy>
。
W10 ISM and DELPHI example by 曹助教
2024-04-23-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
01-德爾菲法-Delphi教材
曹助教 04-準則必要性六點評-廠址選擇-四分位距(必要性+重要性)
2012- Interpreting the Interpretive StructuralModel
(2024/04/20-25日本遊,請假沒上課。回來費了3天做以下筆記)
教學:1.(百度)重要講解明示結構法
範例:2.南華大學 以詮釋結構模型探討旅遊目的地意象及體驗價值因果脈絡關係-以台南市為例
範例:3.義守大學 從複雜到結構:詮釋結構模式法之應用
範例:4.德州理工 Transdisciplinary Collaboration as a Vehicle for Collective Intelligence: A Case Study of Engineering Design Education* | [html]
範例:5.樹德科技 應用詮釋結構模式探討產品設計顧客需求結構分析
参、案例一:加入 WTO 後的高雄地方發展策略之增強結構
“有向圖與二元矩陣是同構的(isomorphic)”
“矩陣稱為有向圖的鄰接矩陣(adjacency matrix)”
“有向圖可以導出可及矩陣,但通常無法直接由從可及矩陣獲得有向圖(Warfield, 1989: 265),而必須經過運 算步驟。”
矩陣的優點在於可以組織與運算大量資訊,但有向圖卻可以提供直觀的 圖形,不需具備豐富的數學能力就可以輕易了解與進行修正。 “經由二元矩陣、有向圖以及有向圖的圖形等一系列的操作,原本存在於 個人腦中的心智模式就可以轉換為可供溝通的具體化結構,接下來將結構中 的元素關係以實質的元素(例如問題、策略、事件等)取代,即完成初步的 詮釋結構模式。”
Zotero
黃: 主要觀點或重要概念。 | 藍: 附加資料,如例子或案例。 | 橘: 個人想法或批評。|紅: 需進一步研究或內容不清。|紫: 引用或重要引述。 | 灰: 次要或一般信息。|
綠: 與研究或工作相關信息。 |洋紅: 統計數據或研究結果。|
(1)- p.12到p.14的 計算過程,有些不明白的地方。
(2)- p.12的表二 確認第一層元素表。我知道(M2表)直行是先導antecedent 點的集合/也知道(M2表)橫列row是後導suceedent 點的集合。但根據定義好像有點顛倒過來的感覺,意義還不是很明白。
肆、案例二:高雄柴山發展問題的解題結構
商量是最好的辦法,而ISM恰是一種好的「溝通、商量的辦法」
ISM(解釋結構模型)是一種處理複雜問題的技術,能夠將混亂的情況轉化為清晰的脈絡,成為政策溝通的平台。
然而,ISM本身只是一種結構化方法,真正有價值的見解仍需來自經驗豐富的專家或關心公共事務的民眾。民眾參與的有效途徑不僅依賴ISM,還需要結合IM(互動管理)程序,以支持民眾參與的各個方面。操作團隊必須熟悉ISM程序,以便有效組織意見,建立符合事實且令參與者滿意的結構模式。使用ISM軟體可以節省時間,減少比較次數,快速處理大量元素,縮短會議時間,並確保參與者在不同階段的會議中保持一致,避免參與者流失,這對代表性強的公共事務案例尤為重要。未來的研究可以更多地利用軟體來協助操作。
• 第一型錯誤(Type I Error): 也稱為偽陽性錯誤,發生在虛無假設(H0)實際上為真,但統計檢定錯誤地拒絕了它。例如,一個未懷孕的人使用驗孕棒,如果結果顯示她懷孕了,這就是第一型錯誤。
• 第二型錯誤(Type II Error): 也稱為偽陰性錯誤,發生在虛無假設(H0)實際上為假,但統計檢定錯誤地未能拒絕它。例如,一個已懷孕的人使用驗孕棒,如果結果顯示她未懷孕,這就是第二型錯誤。
• 第三型錯誤: 有時被非正式地提到,指的是正確地拒絕了虛無假設,但是因為錯誤的原因。例如,一個研究者拒絕了「藥物無效」的虛無假設,因為數據顯示藥物有效,但實際上是因為數據收集過程中的錯誤。
• 第四型錯誤: 也是非正式的術語,指的是採取錯誤的行動,即使統計決策本身是正確的。例如,一個公司根據市場研究決定推出新產品,但市場研究是基於錯誤的消費者群體,導致產品失敗。
這樣區分錯誤的原因是為了幫助研究者和決策者理解在假設檢定過程中可能發生的不同類型的風險,並採取措施來最小化這些錯誤的影響。第一型錯誤和第二型錯誤特別重要,因為它們直接影響到統計推論的可靠性和研究結果的解釋。第三型和第四型錯誤則提醒我們,即使統計分析是正確的,其他因素也可能導致錯誤的結論或行動。
In 範例:4 Transdisciplinary Collaboration as a Vehicle for Collective Intelligence: A Case Study of Engineering Design Education*
工程教育(Engineering Education)是指教授知識和原則以培養工程專業實踐的活動。它包括初級教育(學士和/或碩士學位),以及隨後的進階教育和專業化培訓。工程教育通常還包括額外的研究生考試和在專業工程師監督下的實習,作為獲得專業工程師執照的要求。
舉例來說,工程教育可能包括以下方面:
• 基礎科學和數學教育:為了解工程原理,學生需要有堅實的科學和數學基礎。
• 專業知識培訓:學生會學習特定工程領域的專業知識,如機械工程、電子工程、土木工程等。
• 實驗室和實習:實際操作經驗是工程教育的重要部分,學生通過實驗室工作和實習來應用他們的知識。
• 跨學科合作:工程問題往往需要多學科知識,因此工程教育強調團隊合作和跨學科學習。
• 設計和創新:工程教育鼓勵學生進行創新設計,解決實際問題。
隨著全球化和技術的發展,工程教育正變得越來越國際化,學生和教育機構都在尋求跨國界的合作和知識交流機會。這意味著未來的工程師將需要具備國際視野和能夠在多元文化環境中工作的能力。例如,MIT的新工程教育轉型(NEET)計劃就是一個重塑工程教育未來的嘗試,它強調在未來的產業而非過去的產業中培養工程師。這些教育模式的變化反映了工程教育的國際化趨勢。
- Information and communications technologies are providing new opportunities for international cooperation in education and research especially in Transdisciplinary Collaboration Collective Intelligence.
- An interdisciplinary methodology has been defined as ‘‘two or more disciplines which combine their expertise to jointly address an area of common concern’’.
- There is a need for transdisciplinary research when knowledge about a societally related problems are uncertain, when the concrete nature of problems is disputed, and when there is a great deal at stake for those concerned by problems and involved in dealing with them [17].
- 圖1(Fig.1) 顯示所提出的TD研究過程模型,該模型分為三階段:1)協作定義研究問題目標並建立協作研究團隊; 2)發展集體智慧來解決所討論的複雜問題; 3)TD評估和知識整合。
- Thus, team members can identify and examine cluster interactions internally and interactions between clusters. Clusters will be placed in a sequence by using Interpretive Structural Modeling (ISM) [19].
- 圖2(Fig.2) ISM 這種互動式學習、資訊處理和發展集體智慧法,對於複雜問題所涉及的各個元素之間的複雜關係,做出關係圖特別有用。 這圖包括想法路徑和思考線索,將問題的不清晰且表達不佳的心理模型轉化為可見的、定義良好且相對容易解決的模型。 此過程的根本途徑是利用學術和非學術專家的實務經驗和知識,將複雜的問題分解為較小的子問題,建立更簡單的多層次結構模型。
- Nominal Group Technique (NGT) is an efficient method for generating ideas for defining a set of factors [23]. Five basic steps of NGT process are given as: (a) clarification of a trigger question, (b) silent generation of ideas in writing by each group members, (c) round-robin recording of the ideas, (d) ongoing discussion of each idea for clarification and editing, and, (e) voting to obtain a preliminary ranking of the ideas in terms of significance.
- 圖6(Fig.6) 驅動力driving power和被動(應變)因素dependence(依賴性) 的相關性也在最終的可達性矩陣中計算,如圖 6 所示。,(這個加總的計算方法很重要:我們上課時老師有用到,但課本和範例2,3都省略掉。) 這也是上述問題(2)的解答。
- 圖7(Fig.7) 圖8(Fig.8) 基於有向圖和ISM的模型的形成如圖7所示,透過矩陣的集合和二元關係的關聯現在可以透過使用有向圖(有向圖)理論[25]轉換成圖形形式。 如果因素j和i之間存在關係,則因素之間的聯繫將從i到j。 最後,有向圖被轉換為 ISM,以查看因素之間相互關係的廣泛表示(圖 8)。(3)這部份是須要詳細了解的。
- 圖9(Fig.9) 利用加總過的-驅動力driving power和被動(應變)因素dependence的數字,做出層級區分。
- ??(4) To optimize the team collaboration for collective intelligent (knowledge integration through transactive memory process), interactions between teams within DSM clusters should be maximized and interactions between DSM clusters should be minimized [33].
- After removing the transivities based on the reachability matrix as described in the ISM approach, the digraph (Fig. 7) is converted into the ISM and finally the structural hierarchy of the performance measure factors of SoS is developed as shown in Fig. 8.
- As seen in Fig. 9, they have low driving power and low dependence, hence they can be eliminated from the SoS. For this case, no factor has been identified as an autonomous factor. This indicates that there is no disconnected factor from the SoS.
1.確定元素和直接關係:
- 首先,確定研究中所有相關的元素或變量。例如,若研究供應鏈管理,元素可能包括供應商、製造商、分銷商等。
- 進行一對一訪談或專家小組討論,確定這些元素之間的直接影響關係。
2.建立結構自我互動矩陣(SSIM)self-structural interaction matrix:
- 根據元素之間的關係,建立一個矩陣,記錄元素如何相互影響。例如,若元素 A 影響元素 B,則在相應的格子中標記。
3.轉換為可達矩陣:Reachability Matrix
- 將 SSIM 轉換成可達矩陣,這需要一些數學計算來檢查每個元素的可達性。這一步驟確保瞭解每個元素對其他元素的潛在影響。
4.分級:
- 根據可達矩陣,對元素進行分層,確定哪些元素是基礎層(最底層影響其他元素),哪些元素受到最多其他元素的影響。
5.建立解釋結構模型:
- 最後,基於以上分析,畫出一個層次圖模型,顯示元素之間的影響層次和路徑。
這個計算過程能幫助研究者清楚地視覺化複雜系統中元素之間的關係,並進行有效的結構分析和決策支持 。
- 參考我的筆記關於AHP層級分析法的文章。
W11 AHP
2024-04-30-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
1.Concept of Compromise Ranking
2.Principles And Operation of TOPSIS
3.AI: 紹介します
1.洪哲文尚缺兩必修課: 研究專題、企業倫理;
2.在職班和一般生差別就是7,9年期限;
3,資管組phd的資格考試是:Data Science和Quantitative Research Methods兩科;應於第二學期開學時提出考試申請,約是2024/03考。
4.若4年之內沒有考過,也沒論文發表點數,就退學,若考過就是博士候選人,待論文通過。
5.公立大學課程通常有淘汰標準(down幾%),私大若無此標,則老師為難。標準高則學生跑光,標準低大家過,則水準降低。
- 要做AHP前先做ISM,把問題聚焦!
- 研發要研究「留任」問題!問卷為什麼要設:年資十年以下? (為什麼不設3年以上? 或根本不限制,只問你在研發單位年資多久了?),還有「高端健檢」想了解「回頭」可能性,那高端是怎麼訂?誰訂?答卷者和設計者想發一樣嗎?
- 可找Saaty這書來看:The Analytic Hierarchy Process, McGraw-Hill
層級分析法 Analytic Hierarchy Process
L1目標 - L2構念 - L3準則(或attribute 屬性) - L4方案
做AHP主要在評估-構念和準則的權重。只會給權重。(需要的話L1,L4也可算出權重)
做ISM主要在分出L1--L4階層(與關係)。
方案,講權重很怪,換個比較貼近的講法應說是,比較「偏好」、「喜歡」的方案。(主要研究的是Multiple criteria這層,而非Alternative方案層)
(其實不把方案放出來也可以,因AHP本就只是在研究構念、屬性..這層的權重的。)
權重高的,就是關鍵因素。
DEPHI法也是,找關鍵因素的工具。
p.61 /2
層級架構的型式
- AHP models a decision-making framework that assumes a undirectional hierarchical relationship amon decision levels (Meade and sarkis, 1999)
- The crux of the AHP is to enable a decision maker to structure a prpglem visually in the form of an attribute hierarchy.
- A hierarchy has at least three levels
-- Focus or overall goal of the problem at the top
-- Multiple creteria that defines alternatives in the middle
-- Competing alternatives at the bottom
層級架構的型式(Cont.)
- In AHP, the top element in the hierarchy is the oveall goal. - The hirarchy decomposes from the general goal to a more specific attribute untill a level of manageable decision criteria is met.
(不應該也不可能有個叫'其他'項次。越往上層,構念的命名就越縱合、越抽象,往下的命名就越具體)
集群: 變數集群(PCA 就是在找高度相關性), 還有一類資料集群。Clustering analysis 用K-means方法。這些構念和準則間的關係,就類似於變數集群(相關性高)。 請複習W03-p.14
- 這架構的建立,用PCA或ISM都可以但非必要,但參考文獻也是個辦法。
Delphi主要是問:這與主題的必要性(多強),從開放式到半開放,到評分。找出必要的屬性。(這是為了要建立研究架構)所以是找出relevent。是必不必要,不是重不重要。把必要的都撈進來。
ISM主要功能並非在建立架構。
若研究方法是這三個,則input/output -> input/output:
Delphi(為建立與主題相關的屬性) -> ISM(為了跑網路圖/副業是層級架構) -> AHP
若是這樣做的話:Delphi建架構-ISP確定層級-AHP找關鍵因素
(但通常都會跳過ISM 只跑DELPHI(建屬性與架構)+AHP找關鍵因素)
ISM為了建立鄰接矩陣Adjency Matrix-問卷設計-建議用4分制。(參見W09-p.94 -1/2- 4-point scale) 此矩陣又稱直接影響矩陣。
@照片:直接影響矩陣 這張圖。自己重畫一張
權重會因不同時間、地點、對象的不同而會有波動。所以權重是相對而非絕對的值。
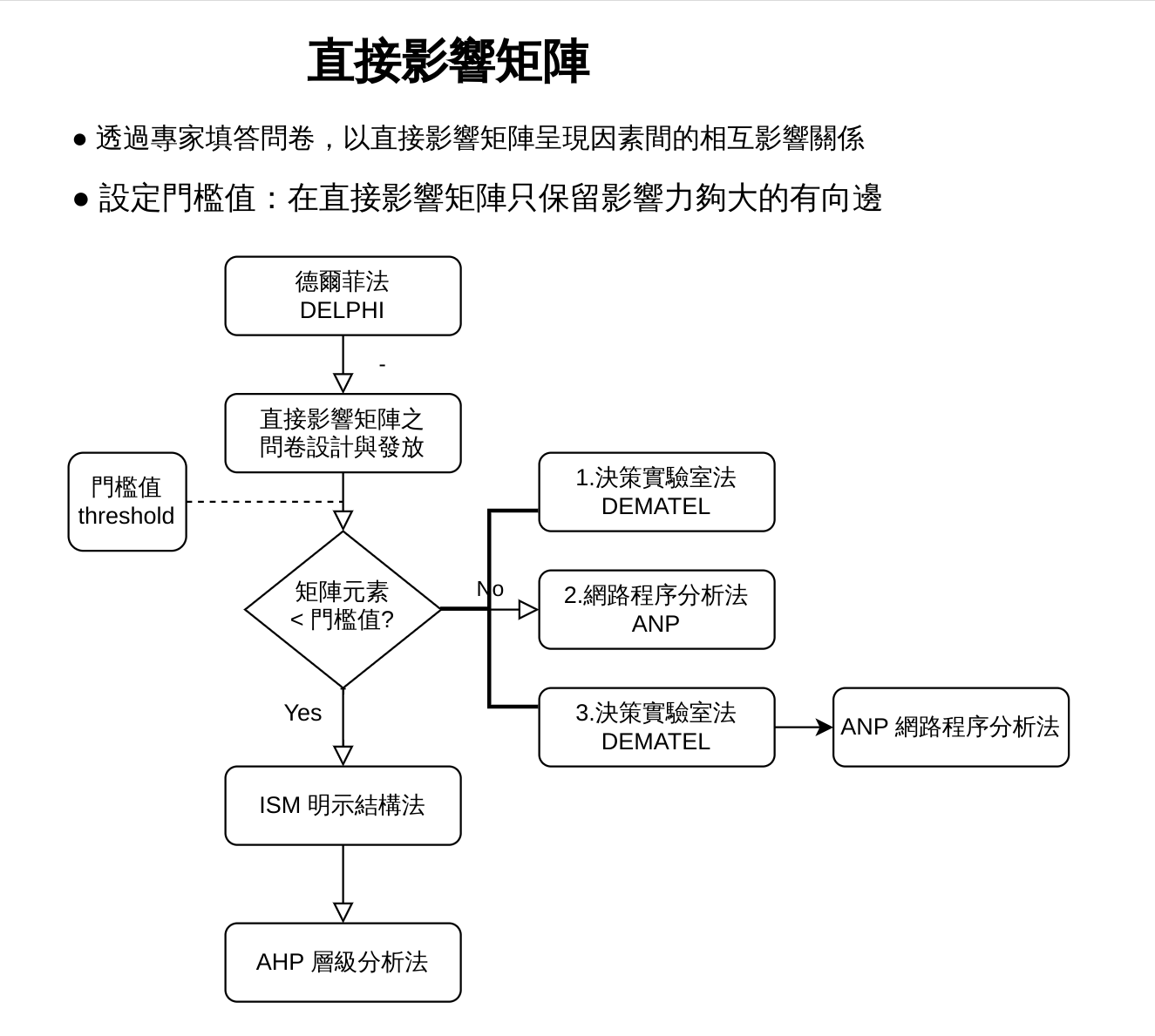
- 透過專家填答問卷,以直接影響矩陣呈現因素間的相互影響關係
- 設定門檻值:及在直接影響矩陣只保留影響力夠大的有向邊
德爾菲法 > 直接影響矩陣之問卷設計與發放
[門檻值] 矩陣元素 < 門檻值 ?
是 Yes: 明示結構法 ->層級分析法
否 No : 1.決策實驗室法; 2.網路程序分析法; 3.決策實驗室法>網路程序分析法
層級架構的型式:
-
p.63 -2
層級架構的優點:
- 具有穩定性與彈性 (如Delphi的Round 1 可以根據專家意見,對層級架構做增刪等等調整。)
p.64 -1/2
層級架構 An example:
- 某航空公司對服務品質的(PZB model)實體評估,找出各屬性的權重。
- 右邊所有權重(overall)數字加總,總要是=1 (Global weights)
- 共有15個準則,會建議:約取5~8個來當做關鍵因素。
購車評估 An example
- TD 或 BU通常研究架構的建立方式是Top-Down(讀文獻&與老師探討)大處著手的方式。先決定幾個大的構念後,再去細究細分。但如果由下往上Buttom-up的話,就要用到PCA(找出重要的構念)這會比較複雜。所以一般是用TD design
- 此處是因屬性不多,所以構念、屬性就沒有分層的必要了。
p.65 -1/2
層級架構 An example:
- 這是「線上服務」品質,建立這個量表是問卷來問主管。(不是問客戶)
- 像補償性 這條就有過爭議,因考慮定型化契約,沒必要列。但後來還是保留。
- 若不是那麼必要,那經過幾個(DELPHI)round 就可能排到很後面去,而被排除了。
p.65 -1/2
層級架構的建立:
- 因子分析(Factor analysis) 通常是因Buttom-up式建架構,所以需要用到。
- 問卷調查或訪談 就是Delphi method
p.66 -1/2
腦力激盪法
- 長官若參加,好像有點奇怪,效果可能不好。
相對權重
- AHP的任務,就是要將這些權重解答出來。(透過問卷)
- 如果W42>W41>W43 注意 W42若改為方案比較 用的符號和>略有差別。用"outrank"符號
p.67 -1/2
整體權重
- AHP透過問卷得到的是Local weights區域權重。經過計算才可得到整體權重Global weights
- weight不能跨區域作比較
- Global weight就是 各層級的weght相乘,就可算出來,有了整體權重就可作比較了。
W12 Principles And Operation of VIKOR 決策實驗室法
2024-05-07-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
3.AI: 紹介します
p.68 -1/2
整體權重 Cont.:
- 如果只做區域權重,只知片面的關係,不知總體Overall的關係。
- 談到Poor English: 早期投稿,很辛苦。潤稿、投稿、郵寄,狀態不明。我沒潤稿郵寄出,半年後收到一疊手寫的review。HTR, poor English。 投國外期刊,潤稿真是很重要。 ISE International Sicience Editing。(以前李國鼎基金會潤稿-一頁80元,很貴,但是不得不的修改方式)。我的英文有那麼差嗎!
- 請看[A3] 構面,底下沒有準則了。這樣情況有可能發生。這時候就要想想這個構面還有沒有需要存在,要仔細考量。(有可能準則被Delphi專家刪了)。
當這個情形時,計算C1..C4時,讓整體權重計算時,用(0.5+0.3) 而不是用(1)來做分母計算。這是個(為了配合A3存在的)權宜之計。這情況少見,但發生過!
成對比較:
- AHP使用成對比較(Pair Wise Comparison),以求取準則或方案間的相對權重或重要性(relative importance, priority weights)
- 將複雜的問題分解為成對的比較,減輕評估者的思考負擔,而能專注在二個要素間的關係
- W公41+W公42+W公43 這樣一組是區域權重,所以加總一定要等於 1 (而W室41+W室42+W室43= 也要是 1)
- 目標 - 購屋層面 - 購屋準則 - 可行方案 (各在自己層級內做比較)
- 方案在準則下作比較,準則在層面下作比較,層面在目標下作比較。
p.69 -1/2
評估尺度:
- Saaty scale: Nine-point intensity scale is employed to reveal the comparative importance between two criteria.
- 兩兩是用倍數做比較: 1:1 或 3:1 或 5:1 ... 9:1
問卷設計:
- 在成對比較問卷設計上,受訪者就湯泉、天闊、壠山林三者就公共設施,兩兩比較之間的相對重要程度(區域權重)
- 勾選越往左邊,就是左邊的比較重要。勾選往右邊就是右比左重要。這樣就可產生比較的倍數關係數字。
- 比完後,再正規化計算,轉成:區域權重。
p.70 -1/2
問卷設計 Cont.:
- 同樣的作法:勾選越往左邊,就是左邊的比較重要。勾選往右邊就是右比左重要。這樣就可產生比較的倍數關係數字。
- 這是:準則在構面下做比較。
問卷設計 Cont.:
- 這只是一種問卷設計。沒有上面那種明白、方便。
-
p.71 -1/2
成對比較矩陣:
- AHP較正式軟體如Export Choice 須收費。
- 沒有sorware套件的話,懂原理也可以用excel操作。
- 如下表的矩陣數字,就是打進excel格子中的數字。
- 依問卷填答結果,產生比較矩陣(是方陣) (pairwise comparison matrix, positive reciprocal matrix)
- 矩陣的乘法和加法-或是本課程最難的部份,把原理搞清處的話。
- PWC方陣,對角線就像是一面鏡子,相對比較成為其reciprocal倒數。(5的倒數是1/5)。
- 其實只要寫好 upper-triangular就好了(lower-triangular 只是倒數)
成對比較矩陣 Cont.:
- n x n 成對比較矩陣又稱為Reciprocal multiplicative prefernce relation.具有以下特質
- Aij>0, Aij= 1/Aji (Multiplicative reciprocal), Aii=1 (對角線)
- n 不宜大於 7(甚至到了5就算很多了)
- 完整的complete 成對比較矩陣: No empty element in the upper-triangular part.
- How many pairwise comparisons will be made for n alternatives under one criterion?
-- Hint: The number of elements in the upper-triangular part. (有n(n-1)/2項須比較,也就是upper-triangular的個數)
p.72~73 -1/2
問卷設計範例:
- 可看看這個範例。
方案於定量屬性下的成對比較:
- 這個範例是沒有出現方案的。
- 一般的AHP主要是研究構面和準則的權重,所以沒有方案的比較多。
- AHP也比較不建議發大量問卷。(不是屬於大眾化題目的研究)
- 若是問消費者,問卷多多益善,至少也要兩三百份,但問專家的話15份可以啦。
- *後來在問卷上,加了一句提示:重要程度排序 A() B() C() 這是幫助填答者思考。因AHP問卷,不像李克特表,有時填答者會不明白作法。
- 注意:這個例子如果已經有成本數字,不該再做成對比較。因pwc是主觀感覺!既然問成本,也有明確數字,沒道理問感覺,而是用成本去計算權重。
- 如果不是成本而是「利潤的話」,計算時不取倒數。 高利潤高權重,高成本低權重。
6/11 交期末專題:怎麼做問曹學姐。
一致性:
- 遞移性 transitivity
- Consistent condition: AijAjk = Ajk (若優i於j A倍,且j優於k B倍, 則i優於k AB倍) 請參考 矩陣upper-triangular的數字
成對比較矩陣的內涵:
- 這是期待,但現實往往有落差,受訪者只是用主觀在填答。很難達到完美。所以我們要恆量,受訪者的答案只要不是偏離太遠的話,即使不完美也應可以接受,這個接受就是「consistency」一致性。
p.75 -1/2
完全一致性:
- 這就是完美的結果,可以當作是一個比較的標準。
- 這一頁很重要,鄧振源的書花好多頁解釋,此處只用一頁說明。
- 遞移性 transitivity
- Consistent condition: AijAjk = Ajk (若優i於j A倍,且j優於k B倍, 則i優於k AB倍) 請參考 矩陣upper-triangular的數字
- Aw = λmax w (這個w 是權重,也稱作是A的特徵向量)
- A:完全一致性 Aw=nw (n是作比較的個數 λmax=n ,而這λmax是期望值)
- 但λmax 通常不會等於n (往往應該是大於n-數學上是可以證明的)
一致性檢定 (很重要的一頁):
- Acceptable consistency是否達成?
- 看Consistency Index一致性指標CI
- CI= λmax - n / n-1,λmax 是矩陣A的最大特徵值(eigenvalue)
- 若CI=0 表示成對比較矩陣具有一致性(λmax=n)
- 可接受一致性:當CI!=0時,建議 0 < CI < 0.1 最佳。
- 實務上若 小於0 絕對是有問題!不正確。那個地方錯了。
- λmax>n 是不一致矩陣,只要不要大太多還是可以接受。若CI < 0.1就是(此問卷具有)可接受一致性。每一個表格都應該有CI值,每個CI值都該在0.1以下才可以通過,若其中有一表格不在0.1以下,此問卷就無效。
- 一般的辨識系統,也是採取這樣的方法做判斷,無法完美,但是有「可接受的一致性」。soft computing或Fuzzy
- 關於Fazzy: Probability機率-會消失,未發生前的預估是機率,但過了時間點就是事實,沒有機率了。但Fazzy不一樣,他是主觀的、程度的概念,是受訪者告訴的,有主觀的偏好,不是客觀估計的。
- 有些老師帶做Fazzy AHP但我帶的學生不這樣做。(覺得會引入受訪者的偏好)
- 權重值高低不關心,重要的是排序,是那個重要。
- 老師的想法是: 如果要做Fazzy研究:就是要尊重受訪者的差異和偏好。每個人對重要與不重要的語意感覺是不一樣的,照說要做Fazzy的話,區間就要非常針對性,很客製化。但怎麼可能所有的Fazzy研究問卷都是一個樣子?
- Fazzy通常會用圖形或區間來表示偏好的不一樣。有模糊的可能沒有模糊的精神。
W13 決策實驗室法與網路分析程序法
2024-05-14-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
1.Principles And Operation of VIKOR
2.Single and Multi-Layer Neural Networks
3.AI: 紹介します
6/11 交期末專題:怎麼做問曹學姐。
p.76 -1/2
一致性檢定 Cont.:
- RI: Random Index; 1x1 就是1階, 11x11就是11階。( reciprocal matrices 就是pairwise matrix)
- 每個成對比較都要有CI 和CR值 (RI是查表得到的 CI是計算出來的) RI是平均的CI值
- 階數: n 看有幾個要成對比較的項目
- 做這個RI表是1970年代,當時的電腦要做出這個表是很不容易的事。
- CI值得產生 請看p.71的[成對比較矩陣]介紹 (隨機產生的矩陣的lower triangular平均值就是)
- 隱含意思是 階數越高一致性越難達成。這是Saaty定義的公式。
- 若 n=5 則應當要 CR<=0.1 所以 CI/RI<=0.1 所以 CI<=0.1RI
此時查表後求出 CI<=0.1 x 1.12 = 0.112 (所以說5階的CI值是算出來的)
Unacceptable Consistancy:
- 如果一致性是不可接受的,只好回頭建議填答者,願意修改或同意修正答案,直至到可接受一致性。所以說
- AHP最好是面訪,不然發大量問卷致填答不理想時(不可接受一致性),就麻煩大了。
- 看p.74[一致性]的例題(理想上2x3=6但往往只能是2x3.=.5或7,總之很難剛好6); 我們用AHP一直在追求可接受一致性,因為想要完全遞移性是很難呀
p.77 -1/2
Unacceptable Consistancy (Cont.):
-
權重的求取:
- 介紹了幾個軟體: 兩週後會找學長來教 跑AHP軟體實做
- Super Decisions可以跑AHP也可以跑ANP
- 用MS EXCEL 可以求出AHP近似結果。鄧振源的書,最推薦MethodI行向量正規化, 和MethodII幾何平均法,兩個方法。
p.78 -1/2
Method I: 行向量正規化:
- Step1: 直行加總。 Step2: 全部做正規化。
行向量正規化 (Cont.):
- Step3: 橫列加總,求出列和。 Step4: 算出權重
- Spte5-7 求CI值。
- Step5: 倆矩陣相乘。 1x0.723+5x0.193+7x0.083 = 2.269
1/5 x0.723+1x0.193+3x0.083=0.587
1/7 x0.723+1/3 x0.193+1x0.083=0.251
- Step6: 算出λmax
- Step7: 這樣就可以算出 CI值了 (公共設施(p.69))
-
p.79 -1/2
行向量正規化 (Cont.):
-
幾何平均法:
- 算術平均 和幾何平均 公式要搞清楚!
-
p.80 -1/2
MethodII: 幾何平均法 (Cont.):
- 參考p.77-2 EXCEL近似法 和其他幾個套件方法ExpertChoice或SuperDecision等 算出的數據不會一樣,但排序應該是一樣的。
- 商管領域的研究,排序遠比數值的精確性重要。
-
群體偏好整合:
- 策略發展或策略探討,問卷的人數就不用多。找專家12-15可也。若是消費者問題研究數字太少偏誤就會非常大。所以胡老師是說:多多益善。
- 研究計算器和excel怎樣開平方、開三次方。
-
p.81 -1/2
事前整合:
- 大家的矩陣數值先整合,再去計算權重。
- 因為資訊來源,通常很少來自單一個來源(問卷來源),很多有時候需要整合。
- 需要把多分整合為一份。用算術或數學平均法會好一點。
事前整合 (Cont.):
- Method II, Majority rule 多數決方法
- 多數決方法 多半不好 (是一種整合資訊的方法) 因為只取單一值,比起算術或數學平均法,風險性高些,就是不那麼可靠。
- 這方法不牢靠,很少用。
p.82 -1/2
事後整合:
- 大家分別算自己矩陣的權重,再用權重去整合。
- 算術平均法。
-
事後整合示例:
- 鄧振原老師的例子整理出來的、可以去看書參考。
-
p.83 -1/2
事後整合示例 (Cont.):
- 比如小半天研究,問業者、消費者兩群體,最好是分開探討,不要整合。
-
事後整合示例 (Cont.):
-
-
-
p.84 -1/2
:
-
:
-
p.85 -1/2
影響填答意願的因素:
- n越大受訪者填答意願就會大大降低。
- 對受訪者而言可能難以比較-所以最好先找人是填答過,已進行修正。
- sampe越少越容易受雜訊干擾。
- 一個構面下面約5,6個準則就很好了。
偏好獨立:
-
-
-
p.86 -1/2
偏好獨立 (Cont.):
-
直接影響矩陣:
- 看W11 p.61
-
p.87 -1/2
直接影響矩陣 (Cont.):
-
直接影響矩陣 (Cont.):
-
p.88 2
層級分析法程序
階段1 建立評估層集結購
階段2 各層集權重計算 (問卷設計發放回收) 建立成對比較矩陣-求取特徵值與特徵向量-一致性檢定
階段3 整體權重的計算 改善策略 或關鍵因素都出來了!
p.125 -1/2
決策實驗室法:
- 曾國雄老師的三本重要的書
-
系統性的改善問題:
- DEMATEL法可以幫忙「找出源頭」幫助做源頭管理
p.126 -1/2
:
- 1976年一篇文章 發展出來的方法
- Fontela E. Gabus A. Current perceptions of the world problematique, in Churchman, C.W. and Mason, R.A. (Eds). World Molding: A Dialogue, North Holland/Elsevier,Amsterdam/New York, 1976
-
Suggested Reading:
- 以下有曾老師、歐陽...等等一些用到DEMATEL的論文
- 很多都是胡老師參加口試,看到一些好方法、好文章,學起來
- 看那篇 automotive industry using grey decision making 汽車行業有關
p.127 -1/2
Delphi + DEMATEL :
- The DEMATEL is used to build a causal diagram or an influential network relation map (INRM) by identifying iterdependence among variables.
- 透過變數之間的相關性,去找出誰是具有最關鍵影響力的因素
:
-
W14 Application of Single and Multi-Layer Neural Networks
2024-05-21-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
決策實驗室法與網路分析程序法實例操作
3.(看輔大資管系)林湘霖老師 10-2:DEMATEL方法 - 方法重要概念
p.127 -2
Delphi + DEMATEL + ANP:
- [建立決策架構]-[直接影響矩陣之問卷設計與發放]-[..]-[產生因果圖]
- 資格考: 定量、決策分析、
p.128 1-2
直接影響矩陣 Direct influence matrix:
- 呈現準則attribute間相互影響關係
- 元素間可能會相互影響,但影響程度未必相同,通常是不對稱的
- 數字表達因素相互影響關係: influence: 0 No, 1 low, 2 medium, 3 height, 4 very heigh,
直接影響矩陣 (cont.):
- (b) --> (a) b對a 有高度影響heigh influence. 若b變大,則a也跟著變大。
- 受訪者需要填答 nx(n-1) 格
- 對角線元素為0。在群體決策下須先求平均矩陣。{(A)+(B)}x 1/2 代表大家的平均意見。
-
正規化影響矩陣:
- 做列和(水平相加) 和行和(垂直相加) 這樣出現10個數,已最大值做為分母。
- 把矩陣內所有數字,除以這個分母。..這就是正規化了。也就是轉換成「程度」了。
p.130 1-2
總影響矩陣:
- 受訪者只要(能)填寫-直接影響數字,間接影響的工作就要讓數學來做了。
- mediators就是間接影響。(b)可以透過很多個mediators去影響到(a)
- 事件連續發生時,把可能性(機率)相乘,就算出影響的強度。
- 把這些經過mediators的影響強度總和起來,就是(b)對(a)的總影響強度。
總影響矩陣(cont.):
- X^2顯示因素間透過任意一個因素擔任中介項相互影響的程度。
- X^2=XX=請看圖形舉例。其實就是矩陣乘法。拿那個位置的列row乘以行colum 的數值加總。
- 所以說「受訪者只要(能)填寫-直接影響數字,間接影響的工作就要讓數學(exclusive)來做了。」
- DEMATEL就是要:算出影響矩陣。
- 其實DEMATEL最麻煩的就是這個計算,幸運的是,如今的人只要知道道理就OK了,計算有Excel來幫忙。
p.130 1-2
總影響矩陣:
- 前提:There is a continuous decreade of the indirect effects along th e posersof X.
- X^m = 0, m-> infinity 無限大。意思是,如果隔的太遠,中間變數越多,會越乘越小,小到幾乎是沒有影響。
- 公式: T = X+X^2+X^3+...= X(I-X)^-1 =直接影響+間接影響+間接影響....
- 注意: I是單位矩陣。 就是對角線都是1 其他都是0的矩陣。I3代表是3個元素的單位矩陣。
- A:方陣, A^-1返矩陣, Excel函數 MINVERSE(A)
-
-
p.131 1-2
總影響矩陣:
-
重要度與關聯度: - (D)列總和+(R)行總和=中心度prominence(重要度) ; D列總和-R行總合=原因度relation(關連度
- (D)列和: 是我影響別人的強度。發出去的。 Send
- (R)行和: 被別人影響的強度。接收到的。 Reciever
- (D)-(R) = 淨影響力
p.132 1-2
因果圖:
- 若D-R是+的話,代表什麼意思呢? 經過抵銷的結果,傾向是影響別人比較多。「導致類」「因」
- 若D-R是一的話,代表什麼意思呢? 經過抵銷的結果,傾向是受到影響比較多。「被影響類」「果」
- 「導致類」應先進行改善,會有事半功倍的效果。
- The evaluation criteria are seldom independent. The causal diagram could help decision makers understand the relationships among dimensions and creteria and thus enable them to propose sound startegies for improvement.
- 評估標準很少是獨立的。 因果圖可以幫助決策者理解維度和具體之間的關係,從而使他們能夠提出合理的改進策略。
- T(總影響矩陣) -> 畫成圖形。畫法是:有數值得地方就可以拉線,畫箭頭。
- 準則少的時候,還看得懂,但準則一多起來(超過5個)看起來就會亂成一團,變得很難看出想知道的因果關係、相互影響關係。
簡化圖形:
- (參考.127) causal diagram = INRM (influential network relationship map)
- 產生因果圖後若要做ANP通常是因為要做方案選擇。
- IRM Impact Relation Map 法,把箭頭弄少一點,(圖)看起來就乾淨了。求平均值(全家總/n,或只有不為0的數做算術平均 )作為門檻值。
- α-cut total influence Matrix-問卷設計-建議用4分制。
- 圖型越複雜問卷就越複雜,很需要簡化,不然-答卷效果會越不好。
p.133 1-2
簡化圖形:
- NRM Network Relation Map 法
- 成對比較法是主流。但斛生老師2015年提出一篇論文:針對關鍵因素,只保留影響每個關鍵因素較大的因果關係。
- 成對比較法->請接著看p.136 a->b 或 b->a 看誰大。只留大的。
-
簡化圖形-影響關係圖:
- 13條線 被簡化到8條線 這就是IRM
-
-
p.134 1-2
簡化圖形-影響關係圖:
-
簡化圖形-影響關係圖:
- D+R=橫軸 D-R=縱軸 標出各點
-
-
p.135 1-2
簡化圖形-影響關係圖:
-
簡化圖形-影響關係圖:
- 用幾何平均 產生門檻值 再砍掉3條線
-
-
p.136 1-2
網路關係圖-成對比較:
- (參見p.133 NRM)
- 成對比較法->請接著看p.136 a->b 或 b->a 看誰大。只留大的。
- NRM 法也可以做簡化。
網路關係圖-成對比較:
- 簡化後 圖形重畫 NRM圖
- 關連度是比較出來的,關連度比較大的-通常都在上方。 你看那些D-R的值
- 就是說:幾乎每個箭頭都是由上往下指去。
- 選題很重要: 當初以為這是個問題,但作到第四章後,不知道怎麼解釋這個問題。第五章(conclusion)無法回應第一章的問題。
- 怎麼解釋在左上方?怎麼改善才會到右上方?這些都是解釋。
- 關鍵因素就是找痛點,找病灶。從果類找「因類」。而不是頭痛醫頭腳痛醫腳。
- 下週講「源頭的找法」,和請學長來分享。
W15 Grey information systems & Grey Relational Analysis, GRA
2024-05-28-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
1.Grey information systems
2. Grey Relational Analysis, GRA
3.AI: 紹介します
p.137 1-2
網路關係圖-成對比較 Cont.:
- 先做IRM(砍掉一些) 再做NRM
- 但老師說 他不大贊成,因為會砍掉一些資訊 infromation loss
- 但往往就是在loss 和 overloading間作取捨。你看圖,本來9個砍掉3個剩6個。
- 可能設定門檻值,會更好些
網路關係圖-成對比較 Cont.:
-
p.138 1
實務應用-消費者購買決策:
- 交大博士論文的有趣方法:DANP: 本來想用DEMATEL+ANP 但是ANP的問卷實在不好填。所以曾國雄老師發展出的一個 DANP方法。
- ABCDE是構面,右邊是題項(準則)
p.138 2:
- 構面先做影響矩陣、再發展總影響矩陣
-
-
p.139 1-2
實務應用-消費者購買決策:
- 注意r = D, s = R 這是D與R的意思,但只是用的符號不同而已。
- 比如1.406 就是b3的b1+b2+b3 列和 ( 字太小 要再核對過)
實務應用-消費者購買決策 Cont:
- 就會畫出這樣的構念圖、5個構念ABCDE都有各自的圖形
- 橫座標x軸是 D+R(r+s) 縱座標y軸是 D-R (r-s)
- 先畫構面的NRM。依據構面間的總影響矩陣。
- 再畫每個構面裏,準則之間的NRM。
- understanding the relationship among dimensions will enable managers to make appropriate desision: The manangers should first improve A, followed by E,D,B and C.
- 這個畫法是目前主流。
p.140 -1,2
網路關係圖 - Hu et al's method 胡老師的方法:
- 只考慮關鍵因素。把a e 的列都拿掉。只看b 和 c d的關係
- 行是看誰影響我最大,所以c行一看就發現b影響我最大。d也一樣,受b影響最大。
:
- 。
-
p.141 -1,2
網路關係圖 - Hu et al's method 胡老師的方法:
- 這些關係可以看這圖去想一想去探索、識別消費者的需求。
-
源頭管理 :
- 線條箭頭減少,圖乾淨,就可看出那個是源頭。有了圖,再進行解釋。
- 。
-
p.142 -1,2
源頭管理 成對比較:
-
-
源頭管理 - Hu et al's method 胡老師的方法 :
- 用這個方法可能可找出多個源頭。
-
p.143 -1,2
實務應用-留任或離職:
- 先決定關鍵因素。找出源頭。找出源頭後再進行解釋(解讀)
-
p.144 -1,2
實務應用-留任或離職:
p.145 -1,2
最適源頭:
- 原則一:關連度為正值的因素,應優先著手改善。
- 原則二:若不好解釋的話。就看p.146 看左上角(急需改善)的象限
p.146 -1,2
最適源頭 Cont.:
-
p.147 -1,2
Delphi + DEMATEL:
- 先做研究架構-再釐清因果關係-最後.
- 最後才做到 關鍵因素分析。
p.148 -1,2
實務應用-競賽獲獎 Cont.:
- .
- 。
p.149 -1,2
Cont.:
- .
- 。
p.150 -1,2
Cont.:
- 可下載來看.網址在右下角
- 。
p.155 -1,2
案例-研發專案計畫評選:
- 這案例也值得看看.網址在右下角
- 以上只講到DANP。而ANP就沒時間講了。
所以應該先用DEMATEL做>畫出網路關係圖,>再進行AHP比較
通常只要注重關鍵因素就好!但:
非關鍵因素-何種狀況下,討論也會帶來影響或好處?
('健檢-提供數位化資訊'本來影響力低不是關鍵因素,在左下角。雞肋。但透過討論,他們覺得對將來有影響,提升聲譽是有好處) 有趣的結果。
最怕就是因果圖很難解釋!也怕受訪者胡弄你!什麼是因?什麼是果?為什麼?怎麼解釋?
- 問卷是DEMATEL和AHP的題項一次發出,一起問
問卷最終就是要合乎common sense,就是不能違背常識。
如果時間夠的話,重發問卷沒問題。問題是博士班可以慢慢來,碩士班時間有限。
基本資料要問(年齡/性別/職務/年資?)
從最容易解釋的開始解釋
最大麻煩還不是投稿,而是怎樣修改、抗爭、辯解、證明,與文獻的對話和呼應(延續或反應)consistant。當然如果你有new finding你是探索型研究,那你可以提出證據,據理力爭。證明你有contribution
第五章: (1)Concluding remarks, General discussion. 與審查者說理、反駁、討論。
(2)Theoretical Implimentations (3)Practical implictions 看看這三點有什麼講法。
最後還可以談談(4)Limitations and Future direction.
準則關聯性DEMATEL問卷調查
某健檢醫院,想做高端(1萬元以上)健檢時,客戶重視的是什麼? 客戶滿意度的研究
OTT服務(英語:Over-the-top media services)是一種透過網際網路直接向觀眾提供的線上串流影音服務,不受ISP網路業者介入,也就是說,不管你用的是哪一家電信網路,只要你的裝置有連上網際網路且符合OTT業者規範(例如:收看需加入會員或是付費等等),就可以收看OTT平台提供的串流影音。
[DEMATEL問卷] |
- 最好有研究架構
- 尺度設計很重要,好不好? 重不重要? 有沒有關連?
關鍵因素有那些- 因果關係為何- 最後提出關鍵改善因素
繪製因果圖: 只要把每行最大值找出來,就可以畫了。列是影響的independent,行是被影響dependent。
D-R為正時就是主動影響因素,負值就是被影響。
為什麼要做正規化: 所有數值在0-1之間,範圍外就是錯了。 才能夠做比較。
- ctrl+sht+Ent. = { } 執行
- minverse 是反矩陣函數
- mmult矩陣相乘
- transpose 橫的轉成直的 位置
[DEMATEL計算] |
請問:
1.績效值公式是什麼? 怎麼算出來的? 就是平均值,抄過來的。(y軸就是績效值)
2.A1,3,5,7是根據什麼挑出來的? 排行前半數 (看排行)
W16 Grey Prediction
2024-06-04-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
AHP
學長Lingo來講AHP: 教用Power Choice軟體使用此軟體 Power Choice® v4.1
或AHP-OS
- 下載軟體
Windows安全性 病毒與威脅防護-管理設定-保護(關閉)
DEMATEL的各個準則間有「關係」的係數,但AHP的準則之間是各自獨立的,是作兩兩比較的。
- AHP經過比較後找出各個準則的權重,根據這權重,可以選出(決定)方案。
- 做準則的權重不只是AHP可以,像DEMATEL也可以算出權重來。
- 做AHP目的是找(決定)方案,做DEMATEL往往是為了找源頭。
- 最後選定的準則,是經過門檻的決定而得出的。(減少準則項次)。
- 問卷的左邊若是n則右邊就是1/n。
- 事前整合-把所有問卷的各欄,先做幾何平均,做好矩陣。事後..
- DELPHI-跟專家來來回回很麻煩,就改用修正式delpi法(先給sample讓專家改)-
- 表6-13 第二次評分結果 要注意 CDI 要低於 0.1(對照一下鄧振源的書)
- 若找不到專家(或文獻沒有),問卷做不出來(關鍵因素找不到,可能沒人做過)只好去訪談,整理其看法出來。
- 系統:
1.新增專案 New project
2.問卷設定 (criterion) 設定3個。 3.0604(專案號碼)-新增子節點-就換產生構面(建3個)-然後構面下面新增子節點-產生準則1,2…
4.選[DELPHI] 份數就是幾個專家填答,一份份的填寫構面和準則(勾選)。 - CDI是變異係數
- 四分位距IQR (IQR)<=2 (Feherty,1879)
- CDI<=0.1 (鄧振源) CDI用excel可以簡單算出來
- 變異數和平均值是可調的,但作者要明白為何這樣設定,必要時要能清楚說明。
- 構面是和構面比。構面裡面的準則是和同構面的準則相比。 (每份問卷都要重覆做)
5.各份問卷都填完後,可選合併計算-然後就:結果顯示。秀出各個準則、構面的權重。而且也可以把整體權重(各準則的)排序排好。
6.最後還可以幫你做好長條圖、圓餅圖出來。
我一邊試做AHP-OS 有些紀錄如下:
- my New project. Session code [A6YWas] (YZEWYM)
- 胡老師會開進階班。 稱胡老師是很厲害的。
W17 MCDM hybrid models and their applications on management issues
2024-06-11-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
3.AI: 紹介します
1.劉格正: 重要或必要因素不是關鍵; 關鍵是最後已有權重的地方,才能找出關鍵因素。
AHP難用大量問卷發放,大量的話(強迫)CI值可能要降到0才好(只能填有限量的題項);(有技巧,有替代性作法-可提供文獻供參考)
-老師說: 有些review請你修改/結果就 石沉大海;
2.劉美周; 根據TAM建立構面與準則; 智能手機線上點餐的-構面與準則研究; 用AHP研究那些是關鍵因素已供決策者參考; 用DELPHI找出重要因素-用AHP找出關鍵因素;
DELPHI的平均數...作為門檻值;挑出重要的因素來做層級架構。
AHP仰賴專家的主觀評價,結果自然帶有主觀性。不同專家看法就可能有所差異。
清晰展現因素間相關性。 (構面與準則來源自?文獻) TAM已發展到好幾代去了..文獻比較舊;多出兩個架構; 博士班的文獻研究要很紮實,像使用TAM就要對其新的發展多來了解;
3.(鴻海)陳明勇 越來越多企業被駭被加密; 資安邊界無遠弗屆,所以要畫出一條邊界來防守。資安要畫層級,要排序,才知道保護對象,那個重要那個可放棄。高階主管連帳號密碼都會被騙走。 直接打不行、駭客就打上下游的供應鍊。
Lingo來教時說 平均數>3 (老師覺得很奇怪! 這是找必要或重要因素,未必要是3可以自己設); 老師問 Chang et al.2002文獻何在?
大陸有對手特地派人來應徵工作,滲入內部。
熱門題目 有Survey的文章,專門去找各種資安相關文章。可多參考。學校sdol資料庫有材料。
ESG會影響資安嗎? (資訊揭露) 構面與準則的來源不夠清楚。
學術來說,文獻為主/經驗為輔; 最怕就是集思廣益弄出來的。
ppt都要設頁數。 (專家的合格性可以設個標準去物色)2/3產業+1/3學術;
4.傅茂文 企業碳排節能困境; DELPI法的CDI 須再了解。
5.htw
6.楊重城: 創業研究, i99 Coffee; 用修正式Delphi法; AHP; 社會企業。
W18 Project demonstration
2024-06-18-Tuesday 18:50-21:50斛生 斛@cycu.edu.tw
專題成果展示
3.AI: 紹介します
關於DEMATEL
- DEMATEL練習題與教材:
• 您可以查看朝陽科技大學提供的DEMATEL決策實驗室法簡報,其中包含了方法介紹和 案例分析。
• 永析統計及論文諮詢顧問網站上有一篇關於DEMATEL分析步驟的文章,該文章提供了一個例子和分析步驟的詳細說明 決策實驗室分析法DEMATEL分析步驟。
• 輔大資管系林湘霖老師 YouTube
上有一個關於DEMATEL方法的範例實作視頻,提供了實際操作的過程和練習素材的連結。
DELPHI的練習資源:
- DELPHI(資料庫)練習題與學習資源:
• Learn Delphi
網站提供了大量的Delphi學習資源,包括免費的視頻課程和書籍,適合初學者到進階學習者。
• コードカキタイ網站上有一篇文章介紹了Delphi的基本概念和學習方法,適合初學者了解Delphi開發環境
Delphiとは?できることや基本的な仕様・学習方法を解説!。
p.103 -1/2
ANP網路分析程序法 Analytic Network Process:
-
p.104 -1/2
馬可夫鍊:
-
p.105 -1/2
馬可夫鍊 Example:
-
p.106 -1
馬可夫鍊-穩定狀態機率:
-
p.106 -2
馬可夫鍊-與網路分析程序法的關連:
-
p.107 -1
獨立性:
-
p.107 -2
相依性:
-
p.108 -1
相依性-Cont.:
-
p.108 -2
相依性-Cont.:
-
p.109 -1
網路圖:
-
p.109 -2
網路圖-Cont.:
-
p.110 -1
內部相依性:
-
p.110 -2
外部相依性:
-
p.111 -1
外部相依性-Cont:
-
p.111 -2
外部相依性-Cont:
-
p.112 -1
層級架構的相依性:
-
p.112 -2
層級架構的相依性-Cont:
-
p.113 -1
成對比較 Car Selection:
-
p.113 -2
成對比較 Car Selection-Cont:
-
p.114 -1
成對比較 Hamburger Model:
-
p.114 -2
成對比較 Product Planning:
-
p.115 -1
超級矩陣 Car Sekection:
-
p.115 -2
超級矩陣-標準型式:
-
p.116 -1
未加權超級矩陣-層級架構網路:
-
p.116 -2
未加權超級矩陣-層級架構網路-Cont:
-
p.117 -1
未加權超級矩陣-層級架構網路-Cont:
-
p.117 -2
未加權超級矩陣-層級架構網路-Cont:
-
p.118 -1
未加權超級矩陣-Product Planning:
-
p.118 -2
層級架構網路-vs-超級矩陣標準型式:
-
p.119 -1
層級架構網路-vs-超級矩陣標準型式-Cont:
-
p.119 -2
未加權超級矩陣 Humborger Model:
-
p.120 -1
加權超級矩陣-Product Planning:
-
p.120 -2
加權超級矩陣-Humborger Model:
-
p.121 -1
極限超級矩陣-Humborger Model:
-
p.121 -2
極限超級矩陣-Humborger Model-Cont:
-
p.122 -1
極限超級矩陣-Product Planning:
-
p.122 -2
極限超級矩陣-AHP層級架構:
-
W17 xxxxxxxxxx
2024-mm-dd二 09:00-12:00 xxxx教授 yyyyyyy
1.今天要講topic or chapter 應從Slide xx講起.
W18 xxxxxxxxxx
2024-mm-dd二 09:00-12:00 xxxx教授 yyyyyyy
1.今天要講topic or chapter 應從Slide xx講起.
胡老師提供參考論文
1.A new hybrid MCDM model combining DANP with VIKOR to improve e-store business (曾國雄 -2012-DANP方法-改良的混合式多評準決策分析。)
2.An Analytic Network Process model for financial-crisis forecasting (We illustrate how the ANP model would be implemented for forecasting the probability of crises.)
3.Comments_on_Multiple_criteria_decision_making
4.Green supplier selection for sustainable development of the automotive industry using grey decision making
5.The evaluation of airline service quality by fuzzy MCDM
6.應用決策實驗室分析法(DEMATEL)與網路層級分析法(ANP)在研發專案計畫評選 (用DEMATEL和ANP法。對紡織所兩個關鍵計畫:「產業用紡織品研究與開發四年計畫」包括十個子計劃提案,與「機能性紡織產業關鍵技術研發四年計畫」包括八個子計畫提案進行評選。本研究邀請了五位專家以權重評分法進行評選,分別淘汰排序較落後的子計畫提案。)
7.結合決策實驗室法與網路程序分析法評估烘焙師傅於國際競賽獲獎之關鍵因素 (用DEMATEL和ANP法。)
8.運用網路程序分析法探討甄選管理師與工程師之關鍵人格特質 (用 Delphi和ANP法。邀請五位高階主管擔任建構正式架構之專家,填寫第一階段之準則重要性專家問卷,後編製 ANP 問卷。填答者為新進管理師與新進工程師之直屬主管)
Backup Data 其他參考資料
Book | Data Miming | Data Science for Business | Data Science and Big Data Analytics |
URL | Kaggle | yelp-Dataset |
▼1 量化研究Youtube
量化研究Youtube
11. Quantitative Research methods1).亞大質性研究L1-2質性研究與量性研究的比較 7min.
2).巨大數據量化研究,其實你可以的,給初學者的入門課
3).巨數揭開量化研究統計分析面紗
4).巨數SSCI論文常見的量化分析方法
5).Quantitative Data Analysis101 Tutorial
結構方程模型(Structural equation modeling, SEM)是一種融合了因素分析和路徑分析的多元統計技術。 它的強勢在於對多變數間交互關係的定量研究。 在近三十年內,SEM大量的應用於社會科學及行為科學的領域里,併在近幾年開始逐漸應用於市場研究中.
1.Jodus學習結構方程模式(SEM)1_概念IBM AMOS
2.巨大數據 【張偉豪統計課】五分鐘搞定SEM論文分析
3.【全球量化研究網】智能寫作輔導系統-量化分析系統(SEM版)
4.【張偉豪統計課】SEM vs. PLS 各有千秋
陳寬裕 16小時學會結構方程模型:SmartPLS初階應用
1.1-1 結構方程模型簡介
2.1-2 PLS-SEM 簡介CB-SEM/PLS-SEM(VB-SEM)
▼2 有幾個類似SPSS的統計軟體
有幾個類似SPSS的統計軟體
在Ubuntu 22.04上,有幾個類似SPSS的統計軟體可以使用:
▼3 折疊3
折疊2
- Lorem ipsum dolor sit amet.
- Lorem ipsum dolor sit amet.